
이번 포스팅에서는 가져온 Raw 데이터를 분석에 필요한 형태로 정리하고 가공하는 부분을 간단히 소개하겠습니다.
앞선 포스트에서 가져온 데이터가 역별/승하차별/시간대별 로 세분화된 이용객 수가 나온 상태라 우리가 궁금한 일평균 이용객수를 보기 위해서 몇 가지 작업이 필요해 보입니다.
python에서 몇가지를 직접 체크를 해봐도 되겠지만, 직관적으로 데이터 이상 여부를 보려고 엑셀에서 csv파일을 열어서 몇 가지 체크를 해봅니다. 물론 데이터 정리 작업 역시 엑셀에서 직접 하고 다시 저장해서 처리해도 무방합니다만 그게 건수가 몇 건 안될 때는 가능하지만 데이터량이 많을 때는 불가능하겠죠.
그래서 전 데이터 변경이나 정리하는 작업은 모두 파이썬에서 직접 처리했습니다.
데이터 변경 내용 살펴보기
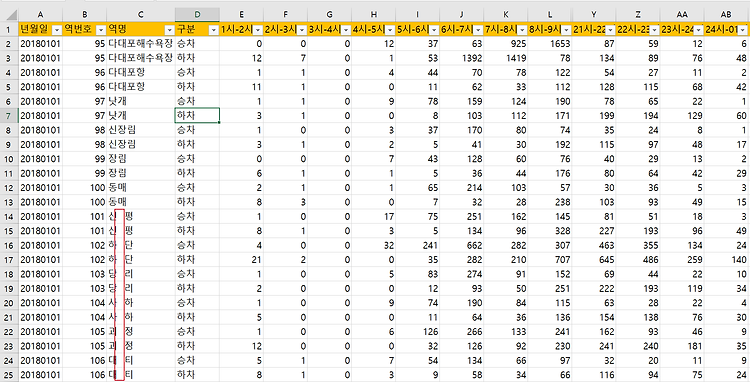
1. 역명의 공백제거하기
데이터를 살펴보니 역명에 모두 붙어서 있는 경우도 있고 공백이 중간에 있는 경우도 있습니다. 이경우 데이터를 조회하거나 처리할 때 은근 신경이 쓰이니 역명 사이나 역명 앞뒤의 공백을 모두 제거해주겠습니다.
2. 데이터 컬럼이름 변경하기
데이터 컬럼 이름도 시간대별이라서 1시~2시, 2시~3시 이런형태입니다. 그냥 깔끔하게 1시, 2시 이런식으로 변경해보겠습니다. 특정 컬럼 1개만 변경할 경우는 컬럼을 지정해서 직접 하면 되는데 이 데이터의 경우는 대부분 변경이 필요해서 모든 컬럼명을 일괄로 변경 처리해보겠습니다.

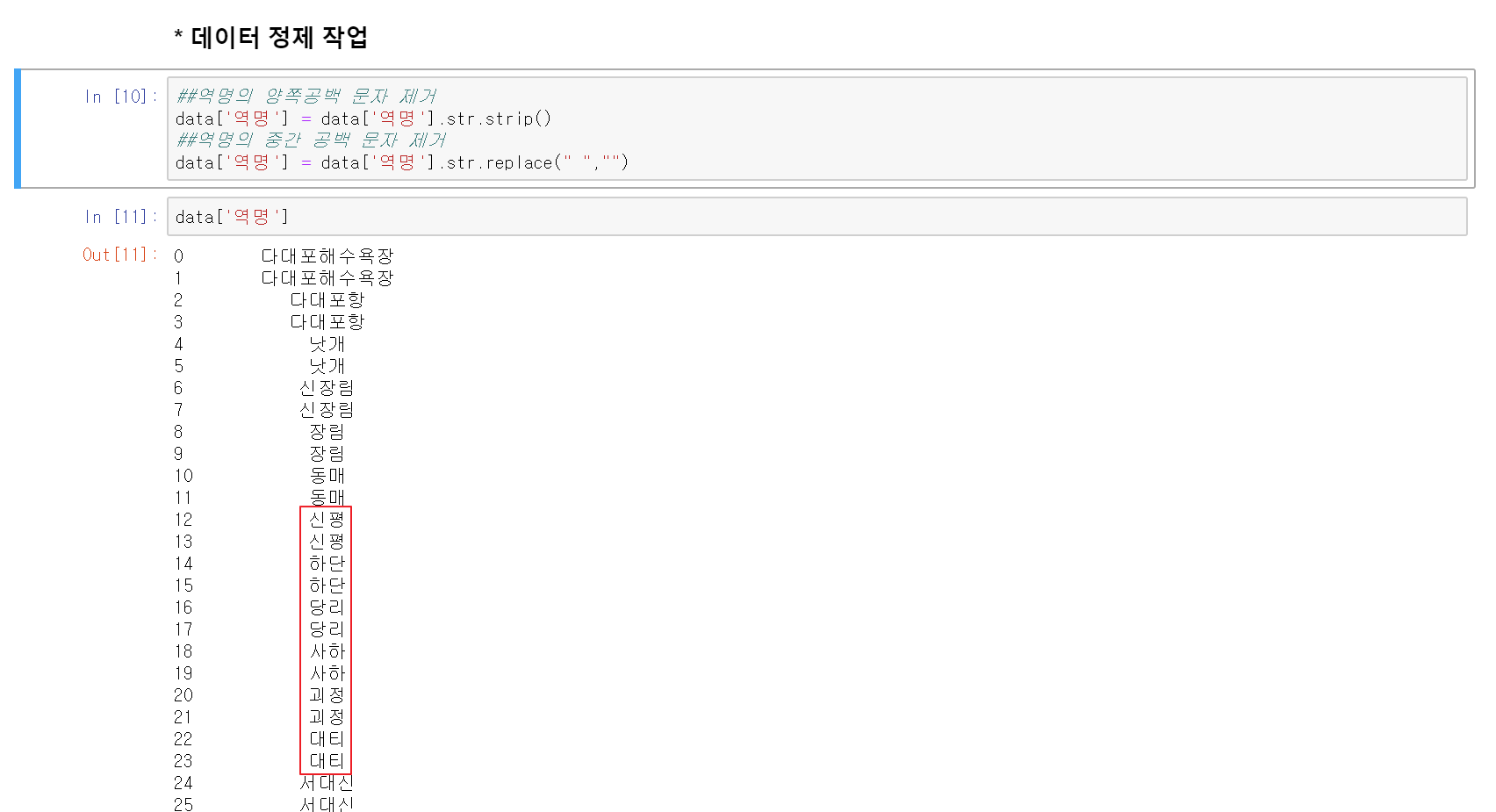
3. 데이터 타입 변경하기
년월일의 경우 날짜 타입이 아니고, 역 번호는 현재 정수형(int)이어서 나중에 데이터를 조작하는데 편리하게 각각 날짜와 문자 타입으로 변경해줍니다. 년월일의 경우 datetime형태로 바로 변경이 안돼서 문자열 변경 후 다시 변경하는 방식으로 진행했습니다.
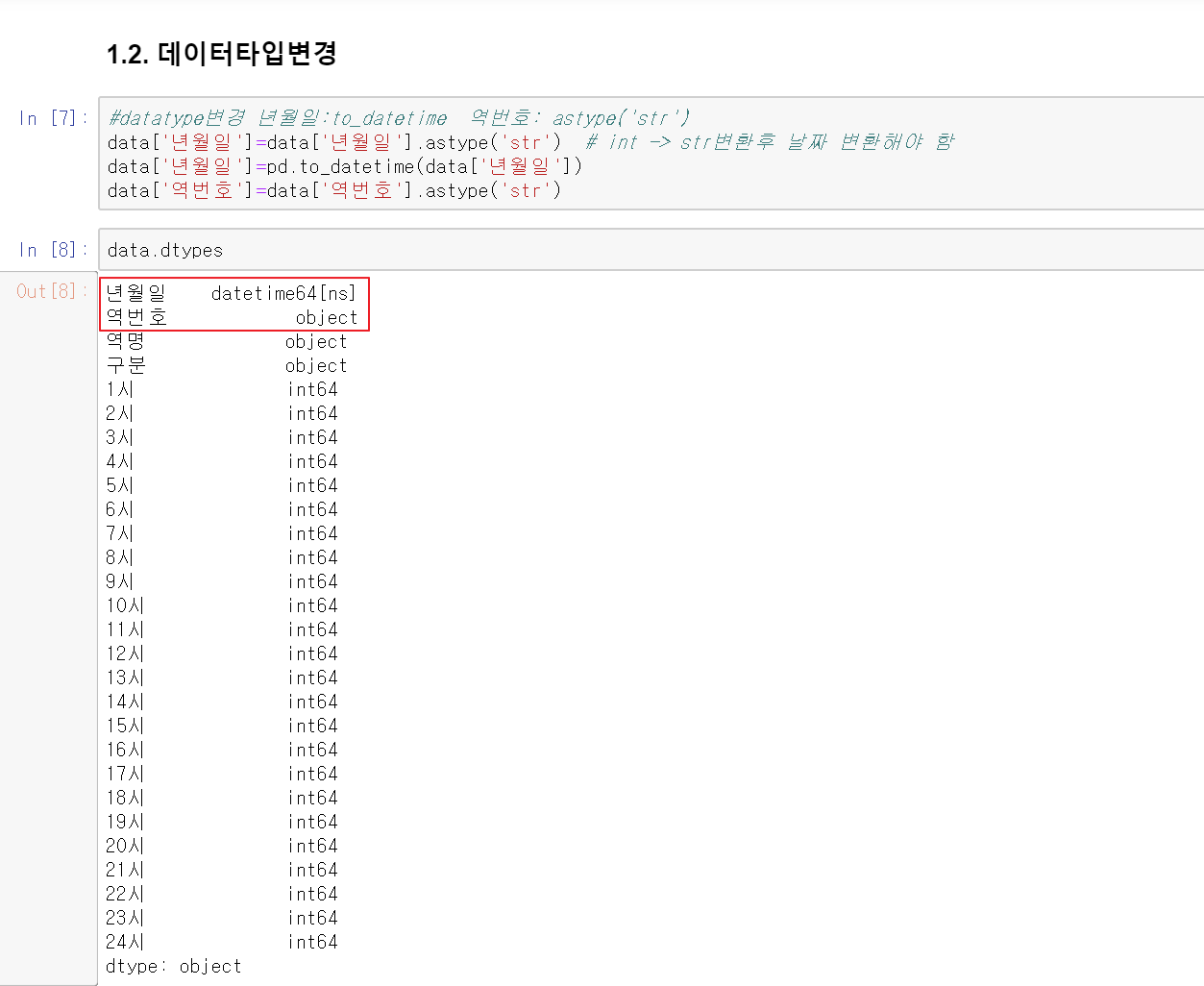
4. 결측 데이터 체크
혹시나 컬럼별로 값이 아예 안 들어간 경우가 없는지 체크합니다. 0 이 아닌 결측 값은 데이터의 특성과 분석하는 내용에 따라서 데이터를 제외하거나 다른 값으로 세팅이 필요하니 꼭 체크가 필요해 보입니다.
5. 데이터 유효성 체크
역별/ 승하차 구분으로 365일의 데이터가 들어 있는지 체크를 해봅니다. 뭔가 잘못되거나 빠진 게 있는지 여기서 검증 후 데이터 보정 등을 해줘야 합니다.
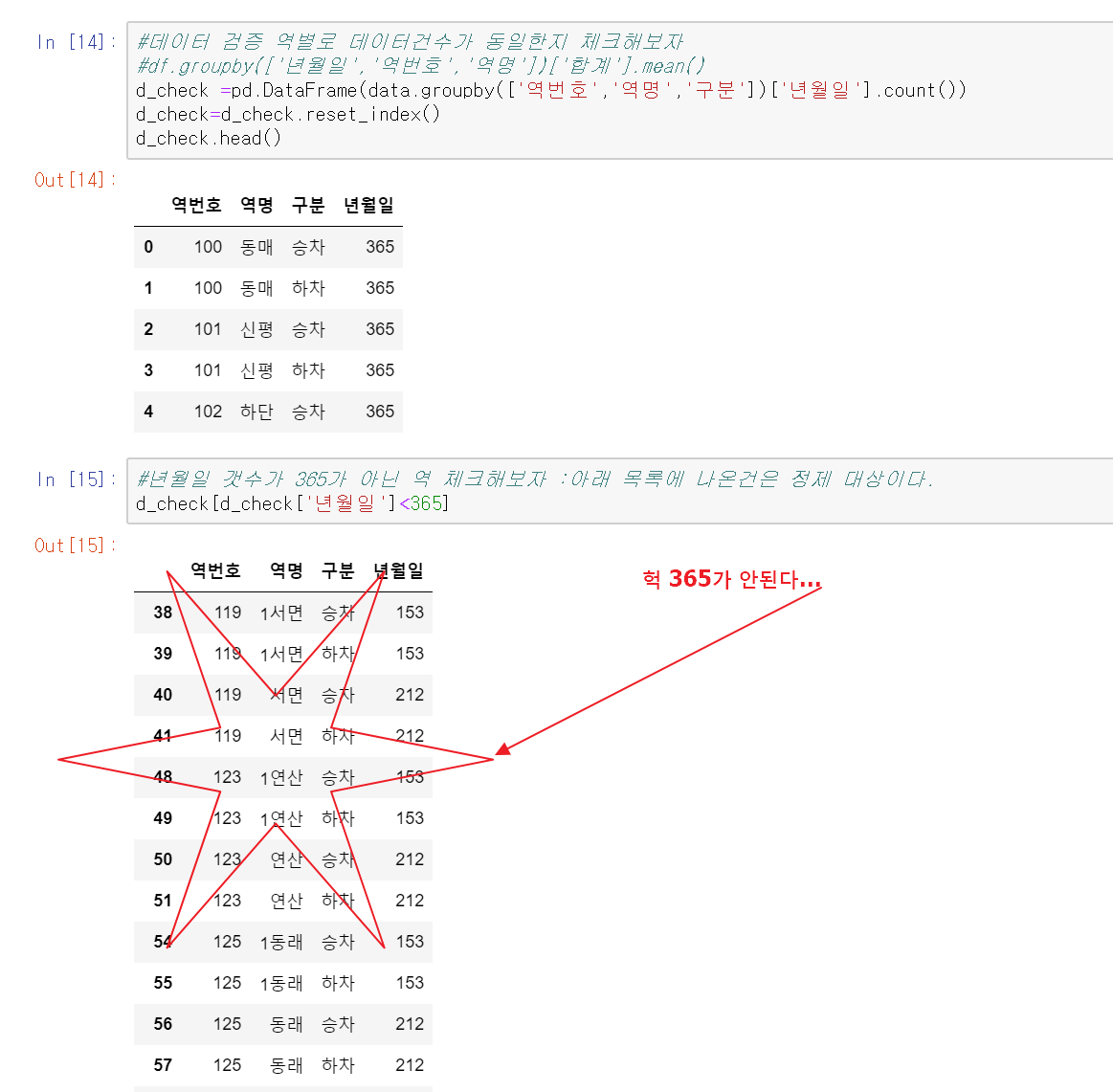
365가 안 되는 게 나와서 살펴보니 역 번호는 같은데 역명이 1서면, 서면 이렇게 다른 경우이네요. 아무래도 2018년중에 역명 표기를 담당자가 바꾼거 아닐까 예상이 됩니다. 대부분 환승역이 있는곳 들이네요. 이경우 역번호 기준으로 역명을 바꿔주며 될것 같습니다. 아무래도 역번호 없이 역명이 구분되게 하려고 한 거 같으니 '서면' -> '1 서면' 이렇게 바꿔주겠습니다.

수업시간에 배운 apply와 lambda함수를 이용해서 처리해보았는데 이게 반복 작업이니 한 번에 처리가 가능할 것 같은데
역명 변경하는 함수를 만들어서 apply를 적용해보려고(한 번에) 했더니 뭔가 잘 안돼서 이번엔 이렇게 처리해줬습니다.
해당 작업은 8만여 건의 데이터를 다 읽어 들여서 해당 조건의 역명을 변경하는 거라 생각보다 시간이 좀 걸립니다.

역명이 아닌 역 번호가 잘못된 경우도 있어서 해당 역 번호를 찾아서 수정해주었습니다.
그 후 다시 365개 안 되는 역이 있는지 체크를 해보았더니 이제 없네요. 데이터 유효성은 이걸로 끝!
6. 정리하며
이번 포스팅은 가져온 데이터 내용을 보고 결측 데이터나 유효하지 않은 데이터가 없는지 체크해보고 보정하는 방법을 알아봤습니다. 이 정제(?)된 데이터로 이제 필요한 작업이 가능할 것 같습니다. 이런 데이터 정제 과정 없이 바로 데이터 분석을 하다 보면 잘못된 데이터 때문에 잘못된 분석이 될 수도 있습니다. 항상 데이터 분석을 들어가기 전에 데이터 이상 유무를 꼭 체크해봐야겠습니다. 다음 시간에는 정제된 이 데이터 파일로 실제로 우리가 원하는 1일 평균 이용객이 가장 많은 역들을 찾아보는 작업을 하겠습니다.
- python 스크립트
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
##역명의 양쪽공백 문자 제거
data['역명'] = data['역명'].str.strip()
##역명의 중간 공백 문자 제거
data['역명'] = data['역명'].str.replace(" ","")
#컬럼 일괄 변경
data.columns = ['년월일', '역번호', '역명', '구분', '1시', '2시', '3시', '4시', '5시','6시', '7시', '8시', '9시', '10시', '11시', '12시','13시', '14시', '15시', '16시', '17시', '18시','19시', '20시', '21시', '22시', '23시', '24시']
data.columns
#datatype변경 년월일:to_datetime 역번호: astype('str')
data['년월일']=data['년월일'].astype('str') # int -> str변환후 날짜 변환해야 함
data['년월일']=pd.to_datetime(data['년월일'])
data['역번호']=data['역번호'].astype('str')
#결측데이터 확인 : 다행이 없음
data.isnull().sum()
#데이터 검증 역별로 데이터건수가 동일한지 체크해보자
#df.groupby(['년월일','역번호','역명'])['합계'].mean()
d_check =pd.DataFrame(data.groupby(['역번호','역명','구분'])['년월일'].count())
d_check=d_check.reset_index()
d_check.head()
#년월일 갯수가 365가 아닌 역 체크해보자 :아래 목록에 나온건은 정제 대상이다.
d_check[d_check['년월일']<365]
# apply() 함수로 데이터를 변경해볼까?
# 역번호 역명 기준으로 가져온 수정할대상을 가져와서 원하는 역명으로 수정 전체 데이터 작업이라 오래 걸린다.
data['역명'] = data.apply(lambda x : '1서면' if (x.역번호=='119') & (x.역명=='서면') else x.역명 , axis=1 )
#역번호 오류 추정 수안역
#7 -> 403 : 수안역
data['역번호'] = data.apply(lambda x : '403' if (x.역번호=='7') & (x.역명=='수안') else x.역번호 , axis=1 )
#데이터 변경후 재검증
d_check = pd.DataFrame(data.groupby(['역번호','역명','구분'])['년월일'].count())
d_check = d_check.reset_index()
#년월일 갯수가 365가 아닌 역 체크해보자
d_check[d_check['년월일']<365]
#정제된 데이터 파일로 저장 : csv로 빠르게 인덱스 없이! 한글깨짐 현상 때문에 encoding필요
data.to_csv('./data2/부산교통공사 시간대별 승하차인원 (2018년)_정제.csv',encoding='ms949',index=False)
|
cs |
'아재도 하는 데이터분석' 카테고리의 다른 글
| [250원] 데이터분석준전문가(ADsP) 자격증 시험후기 (0) | 2019.10.02 |
|---|---|
| [200원] Python 데이터분석 05 - 부산 주요 관광지 근처의 지하철 이용객수 시각화분석(feat by seabon heatmap) (0) | 2019.08.13 |
| [200원] Python 데이터분석 04 -데이터 시각화 (feat by folium) (2) | 2019.08.11 |
| [100원] Python 데이터분석 03 -데이터 프레임조작하기 (groupby) (0) | 2019.08.10 |
| [100원] Python 데이터분석 01 - 부산교통공사 시간대별승하차인원 (4) | 2019.08.08 |
이번 포스팅에서는 가져온 Raw 데이터를 분석에 필요한 형태로 정리하고 가공하는 부분을 간단히 소개하겠습니다.
앞선 포스트에서 가져온 데이터가 역별/승하차별/시간대별 로 세분화된 이용객 수가 나온 상태라 우리가 궁금한 일평균 이용객수를 보기 위해서 몇 가지 작업이 필요해 보입니다.
python에서 몇가지를 직접 체크를 해봐도 되겠지만, 직관적으로 데이터 이상 여부를 보려고 엑셀에서 csv파일을 열어서 몇 가지 체크를 해봅니다. 물론 데이터 정리 작업 역시 엑셀에서 직접 하고 다시 저장해서 처리해도 무방합니다만 그게 건수가 몇 건 안될 때는 가능하지만 데이터량이 많을 때는 불가능하겠죠.
그래서 전 데이터 변경이나 정리하는 작업은 모두 파이썬에서 직접 처리했습니다.
데이터 변경 내용 살펴보기
1. 역명의 공백제거하기
데이터를 살펴보니 역명에 모두 붙어서 있는 경우도 있고 공백이 중간에 있는 경우도 있습니다. 이경우 데이터를 조회하거나 처리할 때 은근 신경이 쓰이니 역명 사이나 역명 앞뒤의 공백을 모두 제거해주겠습니다.
2. 데이터 컬럼이름 변경하기
데이터 컬럼 이름도 시간대별이라서 1시~2시, 2시~3시 이런형태입니다. 그냥 깔끔하게 1시, 2시 이런식으로 변경해보겠습니다. 특정 컬럼 1개만 변경할 경우는 컬럼을 지정해서 직접 하면 되는데 이 데이터의 경우는 대부분 변경이 필요해서 모든 컬럼명을 일괄로 변경 처리해보겠습니다.
3. 데이터 타입 변경하기
년월일의 경우 날짜 타입이 아니고, 역 번호는 현재 정수형(int)이어서 나중에 데이터를 조작하는데 편리하게 각각 날짜와 문자 타입으로 변경해줍니다. 년월일의 경우 datetime형태로 바로 변경이 안돼서 문자열 변경 후 다시 변경하는 방식으로 진행했습니다.
4. 결측 데이터 체크
혹시나 컬럼별로 값이 아예 안 들어간 경우가 없는지 체크합니다. 0 이 아닌 결측 값은 데이터의 특성과 분석하는 내용에 따라서 데이터를 제외하거나 다른 값으로 세팅이 필요하니 꼭 체크가 필요해 보입니다.
5. 데이터 유효성 체크
역별/ 승하차 구분으로 365일의 데이터가 들어 있는지 체크를 해봅니다. 뭔가 잘못되거나 빠진 게 있는지 여기서 검증 후 데이터 보정 등을 해줘야 합니다.
365가 안 되는 게 나와서 살펴보니 역 번호는 같은데 역명이 1서면, 서면 이렇게 다른 경우이네요. 아무래도 2018년중에 역명 표기를 담당자가 바꾼거 아닐까 예상이 됩니다. 대부분 환승역이 있는곳 들이네요. 이경우 역번호 기준으로 역명을 바꿔주며 될것 같습니다. 아무래도 역번호 없이 역명이 구분되게 하려고 한 거 같으니 '서면' -> '1 서면' 이렇게 바꿔주겠습니다.
수업시간에 배운 apply와 lambda함수를 이용해서 처리해보았는데 이게 반복 작업이니 한 번에 처리가 가능할 것 같은데
역명 변경하는 함수를 만들어서 apply를 적용해보려고(한 번에) 했더니 뭔가 잘 안돼서 이번엔 이렇게 처리해줬습니다.
해당 작업은 8만여 건의 데이터를 다 읽어 들여서 해당 조건의 역명을 변경하는 거라 생각보다 시간이 좀 걸립니다.
역명이 아닌 역 번호가 잘못된 경우도 있어서 해당 역 번호를 찾아서 수정해주었습니다.
그 후 다시 365개 안 되는 역이 있는지 체크를 해보았더니 이제 없네요. 데이터 유효성은 이걸로 끝!
6. 정리하며
이번 포스팅은 가져온 데이터 내용을 보고 결측 데이터나 유효하지 않은 데이터가 없는지 체크해보고 보정하는 방법을 알아봤습니다. 이 정제(?)된 데이터로 이제 필요한 작업이 가능할 것 같습니다. 이런 데이터 정제 과정 없이 바로 데이터 분석을 하다 보면 잘못된 데이터 때문에 잘못된 분석이 될 수도 있습니다. 항상 데이터 분석을 들어가기 전에 데이터 이상 유무를 꼭 체크해봐야겠습니다. 다음 시간에는 정제된 이 데이터 파일로 실제로 우리가 원하는 1일 평균 이용객이 가장 많은 역들을 찾아보는 작업을 하겠습니다.
- python 스크립트
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
##역명의 양쪽공백 문자 제거
data['역명'] = data['역명'].str.strip()
##역명의 중간 공백 문자 제거
data['역명'] = data['역명'].str.replace(" ","")
#컬럼 일괄 변경
data.columns = ['년월일', '역번호', '역명', '구분', '1시', '2시', '3시', '4시', '5시','6시', '7시', '8시', '9시', '10시', '11시', '12시','13시', '14시', '15시', '16시', '17시', '18시','19시', '20시', '21시', '22시', '23시', '24시']
data.columns
#datatype변경 년월일:to_datetime 역번호: astype('str')
data['년월일']=data['년월일'].astype('str') # int -> str변환후 날짜 변환해야 함
data['년월일']=pd.to_datetime(data['년월일'])
data['역번호']=data['역번호'].astype('str')
#결측데이터 확인 : 다행이 없음
data.isnull().sum()
#데이터 검증 역별로 데이터건수가 동일한지 체크해보자
#df.groupby(['년월일','역번호','역명'])['합계'].mean()
d_check =pd.DataFrame(data.groupby(['역번호','역명','구분'])['년월일'].count())
d_check=d_check.reset_index()
d_check.head()
#년월일 갯수가 365가 아닌 역 체크해보자 :아래 목록에 나온건은 정제 대상이다.
d_check[d_check['년월일']<365]
# apply() 함수로 데이터를 변경해볼까?
# 역번호 역명 기준으로 가져온 수정할대상을 가져와서 원하는 역명으로 수정 전체 데이터 작업이라 오래 걸린다.
data['역명'] = data.apply(lambda x : '1서면' if (x.역번호=='119') & (x.역명=='서면') else x.역명 , axis=1 )
#역번호 오류 추정 수안역
#7 -> 403 : 수안역
data['역번호'] = data.apply(lambda x : '403' if (x.역번호=='7') & (x.역명=='수안') else x.역번호 , axis=1 )
#데이터 변경후 재검증
d_check = pd.DataFrame(data.groupby(['역번호','역명','구분'])['년월일'].count())
d_check = d_check.reset_index()
#년월일 갯수가 365가 아닌 역 체크해보자
d_check[d_check['년월일']<365]
#정제된 데이터 파일로 저장 : csv로 빠르게 인덱스 없이! 한글깨짐 현상 때문에 encoding필요
data.to_csv('./data2/부산교통공사 시간대별 승하차인원 (2018년)_정제.csv',encoding='ms949',index=False)
|
cs |
'아재도 하는 데이터분석' 카테고리의 다른 글
| [250원] 데이터분석준전문가(ADsP) 자격증 시험후기 (0) | 2019.10.02 |
|---|---|
| [200원] Python 데이터분석 05 - 부산 주요 관광지 근처의 지하철 이용객수 시각화분석(feat by seabon heatmap) (0) | 2019.08.13 |
| [200원] Python 데이터분석 04 -데이터 시각화 (feat by folium) (2) | 2019.08.11 |
| [100원] Python 데이터분석 03 -데이터 프레임조작하기 (groupby) (0) | 2019.08.10 |
| [100원] Python 데이터분석 01 - 부산교통공사 시간대별승하차인원 (4) | 2019.08.08 |