지난 포스팅에서는 데이터 분석을 하기 전에 제공된 데이터셋의 유효성 체크를 하고 약간의 보정을 했었습니다.
이제 본격적으로 원하는 데이터를 만들어보겠습니다.
참 우리가 원하는 데이터는 바로 역별 1일 평균 이용객수이지요.
기본적으로 시간대별로 나누어져 있으니 이걸 합하고, 승/하차 구분이 되어 있으니 이것 역시 합해서 평균을 내주는 방식으로 접근하면 될 것 같습니다. 중요하건 365일에 대한 데이터이니 이걸 일평균으로 다시 한번 해줘야 하고요.
이제 차근차근 진행해 보겠습니다.
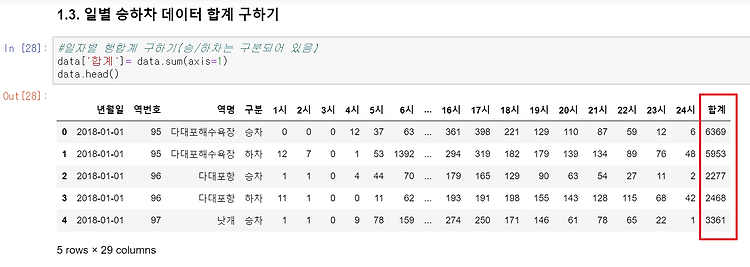
1. 우선 시간대별 되어 있는 이용객수를 합(sum)해서 '합계'라는 컬럼을 추가해 보겠습니다.
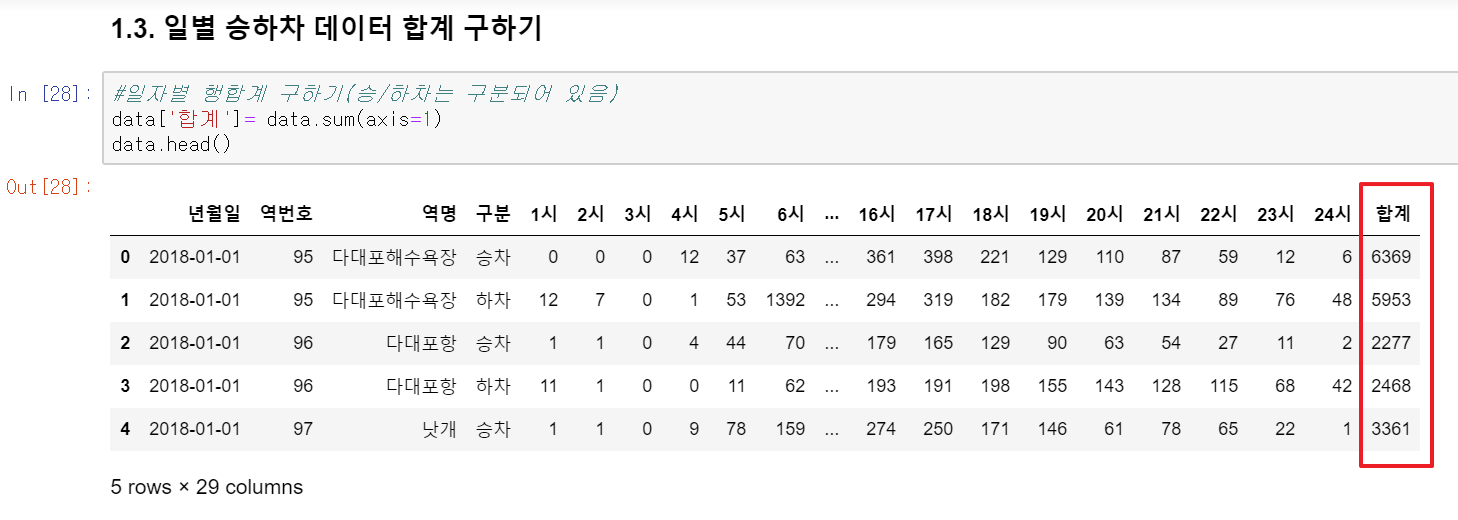
2. 여기서 우리가 필요한 컬럼만 다시 가져와서 새로운 데이터 프레임에 저장합니다. 사실 우린 합계만 필요하니 아래처럼 필요한 컬럼만 가져와서 새로운 데이터 프레임을 만듭니다.
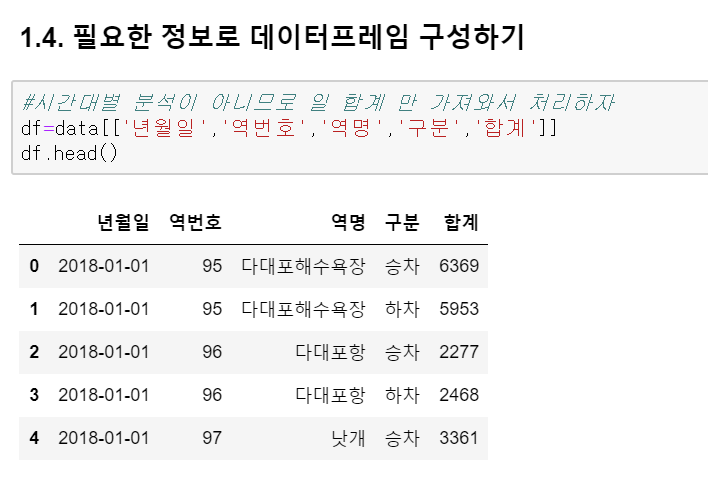
3. 이제 승차/하차로 구분된 이 값을 일자별로 평균값을 구해서 구성해보겠습니다. groupby를 사용합니다.
이경우 주의할 부분이 실제 데이터는 합계라는 컬럼 1개라서 데이터 프레임이 아닌 시리즈로 구성된다는 점입니다. 데이터 프레임일 때와 시리즈일 때 적용하는 메서드가 달라지므로 시리즈를 데이터 프레임으로 만들어줘야 합니다.
4. 데이터 프레임으로 처리 후 인덱스 리빌드를 해주었습니다. groupby로 할 때 group으로 묶었던 연월일/역 번호/역명이 결합된 인덱스로 만들어져 버립니다. 이경우 각각 컬럼으로 접근이 불가능합니다. 따라서 인덱스를 새로 리셋(reset_index)를 해주면 해당 컬럼들이 이제 각각 개별 접근이 가능한 컬럼 형태로 바뀝니다.

5. 합계 컬럼을 알아보기 쉽게 '이용객수'로 변경하겠습니다. 이경우는 한컬럼만 변경이라 다른 명령어로 해주면 되는데 컬럼명과 컬럼값 수정 방법은 LAB OF DAEGON 님의 포스트를 참고하시면 됩니다.
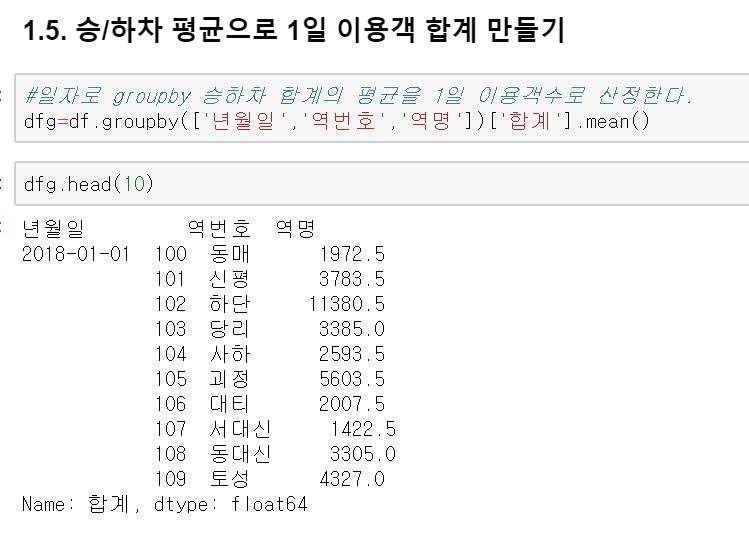
6. 이제 승/하차의 평균값으로 1일 이용객이 나왔습니다. 이제 365일의 평균을 구해야겠지요. 다시 한번 groupby로 1년 1일 평균 이용객을 구해보겠습니다. 이번엔 시리즈를 바로 DataFrame으로 만들기까지 하겠습니다.

위에 보시면 데이터 프레임으로 전환은 됐지만 역 번호/역명이 결합 인덱스로 지정되어 나중에 개별 컬럼형태로 역 번호, 역명으로 접근이 안됩니다. 이경우 어떻게 한다고 했죠? 맞습니다. 위에 했던 index rebuild를 해주면 됩니다. 그럼 현재 결합된 인덱스가 개별 컬럼으로 바뀝니다. 쥬피터 노트북에서 실행된 결과 값이 보시면 같은 줄로 표시가 안 된 경우 해당 부분이 컬럼이 아닌 인덱스로 설정된 걸로 보셔도 무방합니다.
7. 이렇게 만들어진 역별 이용객수를 이제 정렬을 한번 해보겠습니다.(아직 인덱스 리빌드 전입니다.) 짜잔~ 상위 20개만 보니 이제 이용객이 가장 많은 역이 보입니다. 역시 서면역이 당당히 1위(1,2호선 각각 입구가 틀려서 별도로 집계되는 것 같습니다. 이처럼 환승역인 경우 역 전체 이용객을 아마 합해서 실제 역전체 이용객수를 구해야겠습니다)이고요 그다음 바로 사상역이네요~ 여러분 예상과 같나요? 저의 예상과 전혀 다른 역이었습니다.

다음 포스팅에는 이렇게 일별 나온 데이터로 시각화를 해서 좀 해보겠습니다.
간단히 바 그래프와 함께 지도 위에 이용객이 많은 지역들을 표시도 해보겠습니다.
다음 포스트를 기대해주세요.
'아재도 하는 데이터분석' 카테고리의 다른 글
| [250원] 데이터분석준전문가(ADsP) 자격증 시험후기 (0) | 2019.10.02 |
|---|---|
| [200원] Python 데이터분석 05 - 부산 주요 관광지 근처의 지하철 이용객수 시각화분석(feat by seabon heatmap) (0) | 2019.08.13 |
| [200원] Python 데이터분석 04 -데이터 시각화 (feat by folium) (2) | 2019.08.11 |
| [150원] Python 데이터분석 02 -데이터 정리 (4) | 2019.08.09 |
| [100원] Python 데이터분석 01 - 부산교통공사 시간대별승하차인원 (4) | 2019.08.08 |