이번 포스팅에서는 지난번 도시철도 일자별 승하차 이용객수 데이터를 가지고 부산의 주요 관광지가 있는 곳의 주요 역들의 이용형태를 한번 파악해보겠습니다.
기본적으로 부산하면 해운대나 광안리가 떠오르시는 분이 많은데, 이런곳들은 역시 해수욕장 근처라 아무래도 여름휴가철에 도시철도역 이용객도 좀 많지 않을까요? 그리고 1년에 한 번 하는 광안리 불꽃축제 때는 아무래도 이용객수가 급증할 것 같은 건 어느 정도 예상해볼 수 있죠. 지하철 이용객수만으로 관광지 혹은 특별한 이벤트(축제)와 관련이 있는지 한번 살펴보는 게 이번 포스팅의 목적입니다.
분석대상 역은 아래와 같습니다. 일단 부산교통공사의 문화관광 카테고리의 시티투어-호선별 관광정보를 참고했습니다.
아직 저도 못가본 곳이 많네요. 참고로 도시철도로 떠나는 부산여행 이란 PDF문서도 있으니 참고하시면 좋을 것 같습니다.
- 1호선 : 괴정/하단/토성/자갈치/남포/범어사
- 2호선 : 장산/동백/센텀시티/광안/경성대부경대
기본적으로 이번에는 역별로 일자별로 되어있는 가공된 전체 데이터를 가지고 우리가 보고 싶은 역들의 정보로 데이터 프레임을 가공하는데 초점을 두겠습니다.
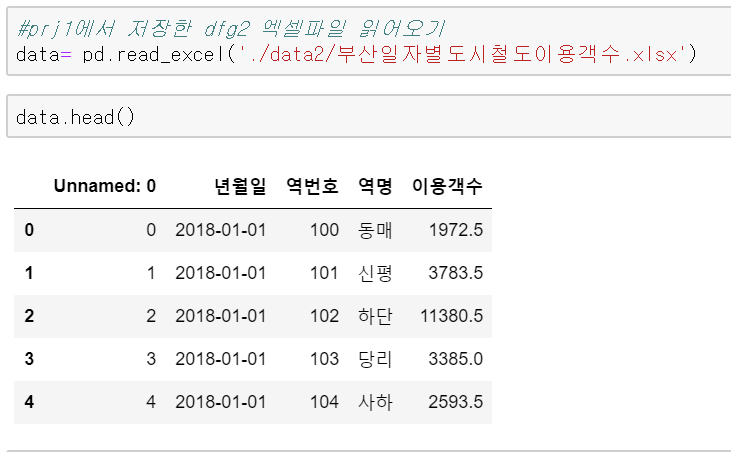
아래 왼쪽처럼 된 데이터를 가지고 우리가 보고 싶은 역들의 정보로 만들어보겠습니다.
 |
 |
방법론 상으로는 역별로 해당 이용객수를 가져와서 새로운 데이터 프레임으로 추가를 해주면 되는 거고, 그 칼럼명을 이용객수가 아닌 역 이름으로 바꿔주면 되겠지요.
왠지 반복되는 작업이 될 수 있어서 함수를 데이터 프레임을 이렇게 만들어주는 함수를 하나 만들어보겠습니다.
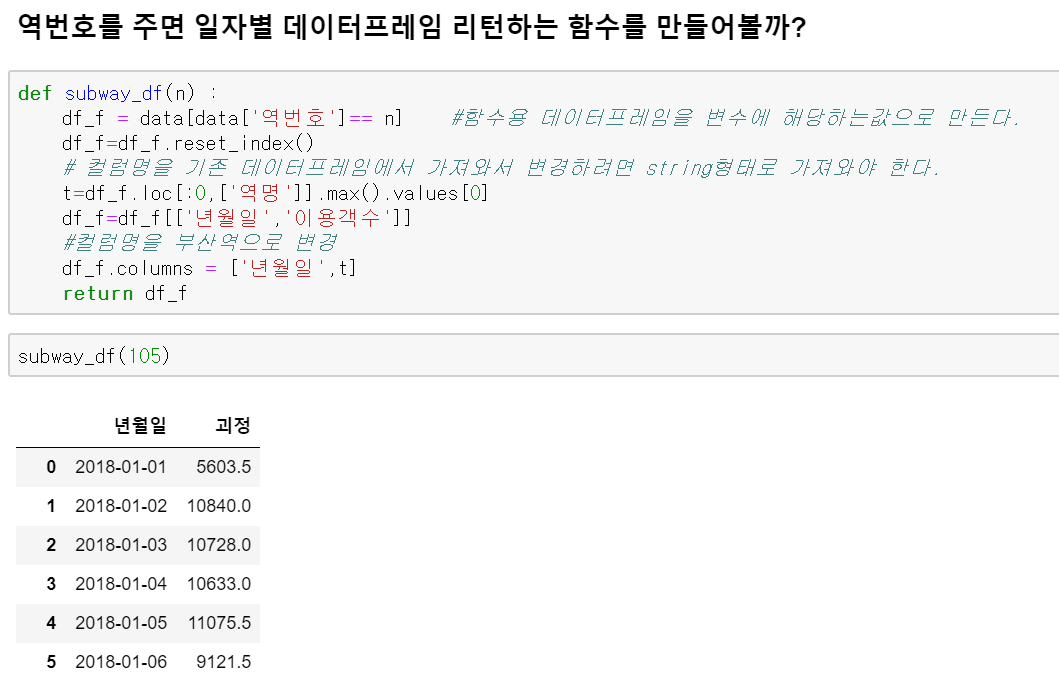
이제 만들어준 subway_df 함수를 이용하면 역 번호만 주면 우리가 원하는 데이터 프레임이 만들어집니다.
분석하고 싶은역 번호를 확인해서 아래처럼 만들어줍니다. 이것 역시 반복작업이니 역번호를 리스트로 만들어서 뭔가 돌리면 쉽게 만들어질 것 같기도 하고요.

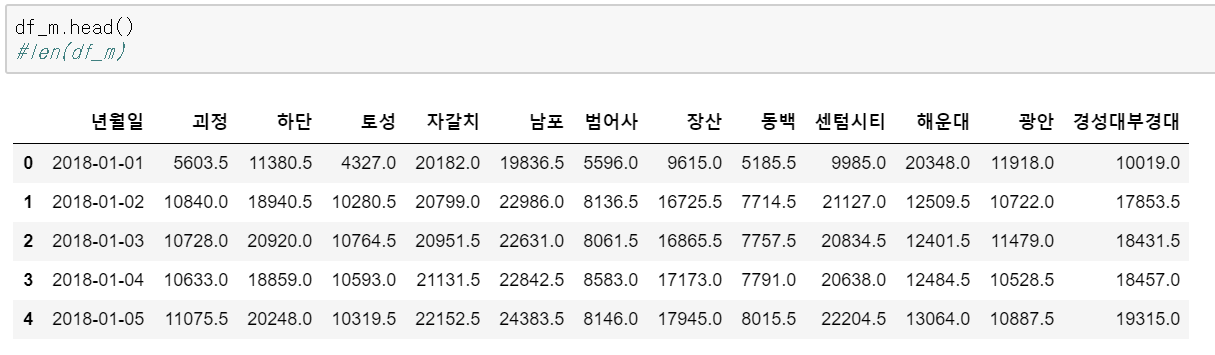
각각 만들어진 데이터 프레임을 이제 이제 merge로 합쳐보겠습니다. 어차피 인덱스 기준 merge라 별다른 명령어 없이 아래처럼 해주면 가능합니다.
분석을 조금 편하게 하기 위해서 1호선 역들과 2호선 역으로 나누었습니다.
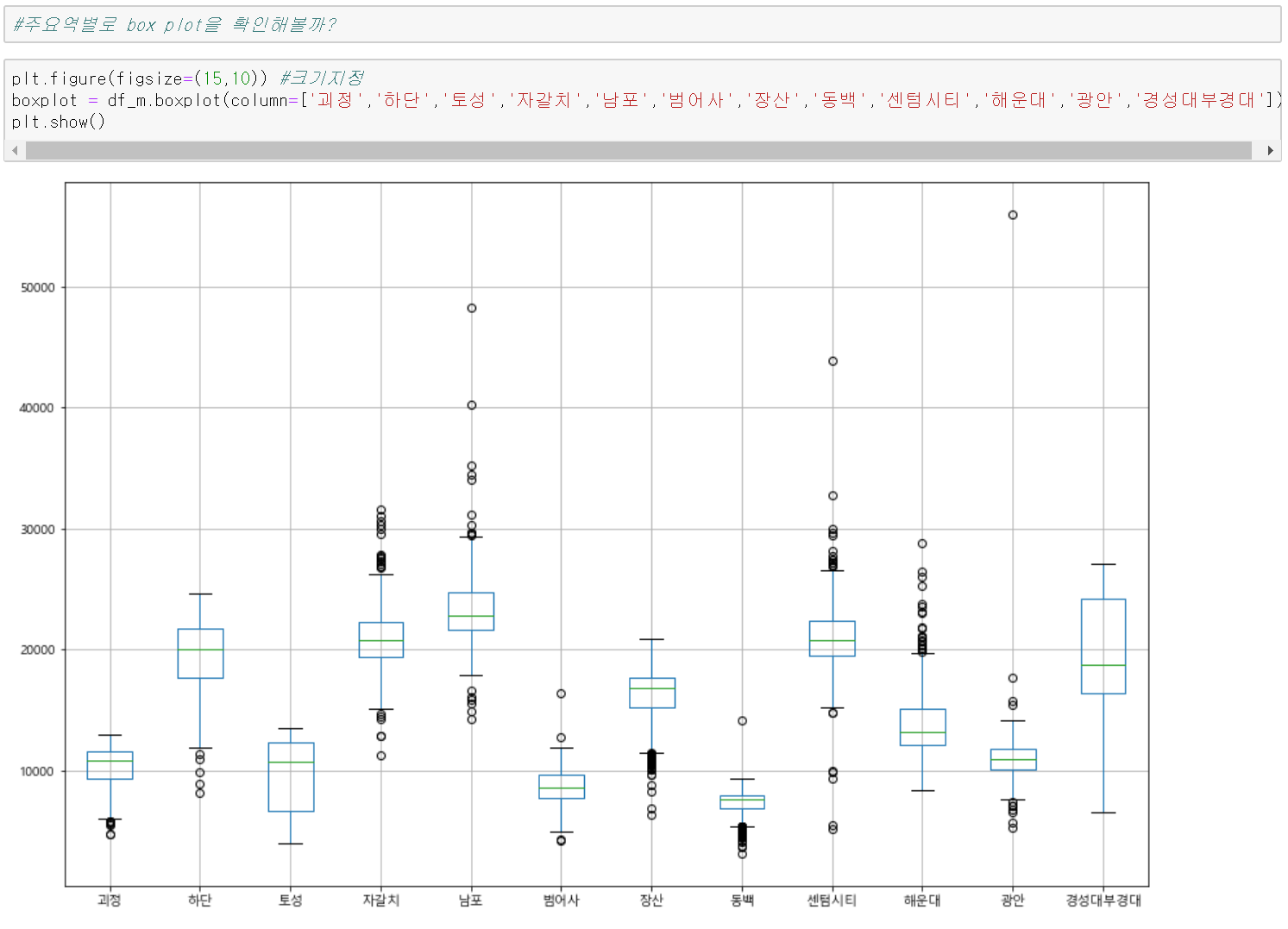
이렇게 만들어진 데이터 프레임은 아래와 같습니다. 일단 만들어진 데이터셋을 가지고 상자 그림을(BOXPLOT)을한번 그려보겠습니다.

상자 그림은 데이터를 볼 때 평균과 퀀타 일이라고 부르는 25% 75% 구간 파악이 쉽고 이상치(Outlier)를 발견하기 쉽게 해 주는 통계적 분석 방법 중에 하나죠~ 박스의 크기를 보면 이용객 평균이 더 많은 곳(전체 이용자 수)을 추측이 가능하죠 물론 평균이 비슷하다고 할 때 말이죠. 하단과 경성대부경대역을 비교하면 평균이 20,000과 18,000 정도인데 박스의 두께를 보면 경성대 부경대역이 이용객이 더 많아 보입니다. 이상치의 경우 평균 이용객을 월등이 넘어서는 날인데 광안의 경우 유독 1개의 데이터가 튀네요. 그밖에 남포, 자갈치 센텀시티, 해운대는 평균보다 높은 이상치 데이터가 많이 보이고요.
장산과 동백, 괴정의 경우는 평균 이하 이상치가 많네요. 이상치 데이터도 한번 확인해보면 재미있을 것 같네요.
분석을 하기엔 너무 세부적인 것 같아서 월, 주, 요일 단위로 분석을 하기 위해 해당 데이터 프레임에 월, 주, 요일을 구해서 새로운 컬럼으로 추가해보겠습니다.
월은 dt.month로 해결이 되는데 주는 찾아보니 연월일을 weekofyear란 메서드로 변환이 가능하네요.
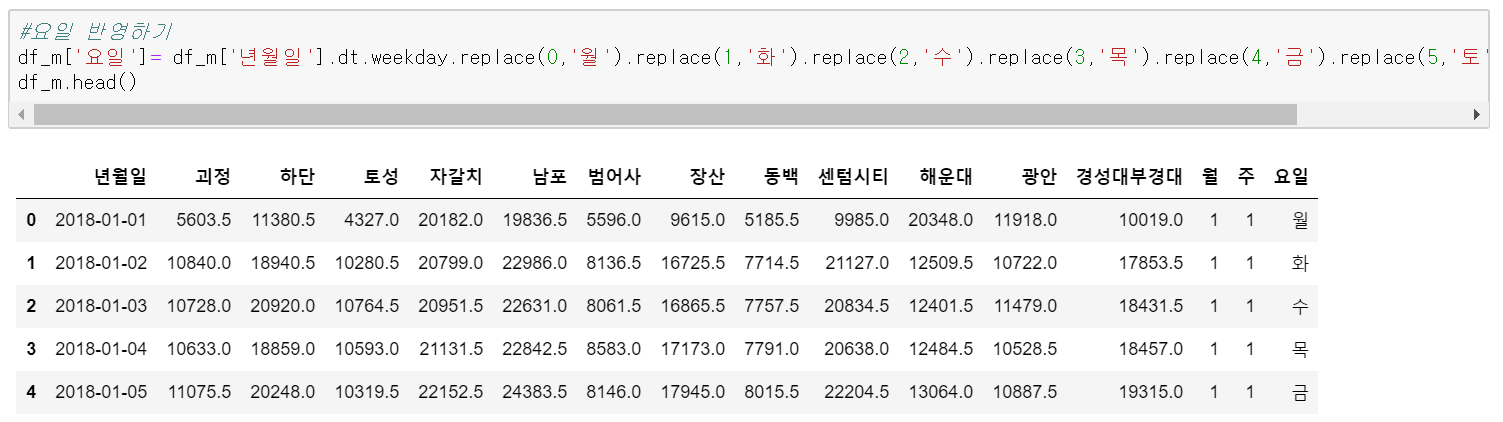
주중과 주말에도 왠지 차이가 있을듯해 보이니 월보다는 주 단위가 세부적일 것 같아서 해보았는데, 추가적으로 요일을 넣어보겠습니다. 주의 경우는 weekday를 사용했고 월, 화, 수, 목, 금, 토, 일로 변경은 replace명령어로 처리해줬습니다.
이제 월, 주, 요일이 만들어졌으니 월 단위로 groupby로 월평균 이용객수를 뽑아보겠습니다.

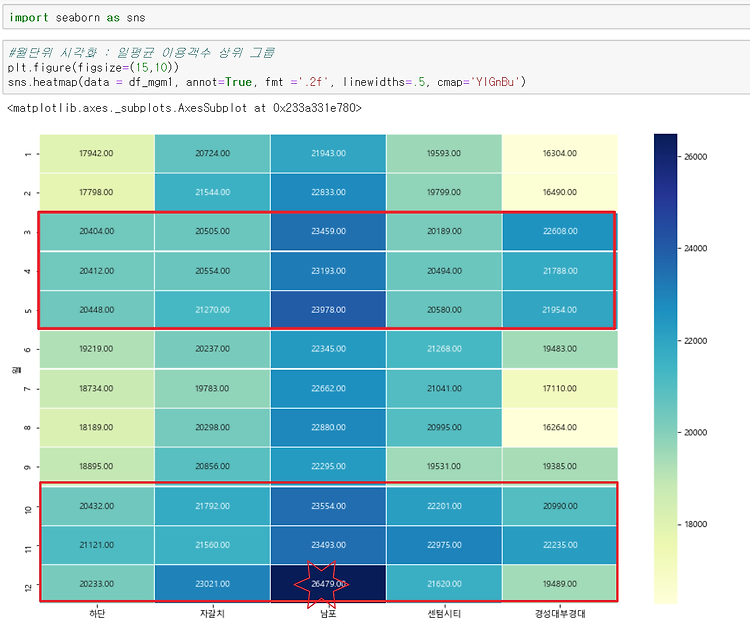
그룹을 이용객수 기준으로로 3개의 그룹으로 나누어서 보겠습니다. heatmap으로 표시할 때 모든 역을 표시하면 가장 큰 수와 작은 수 기준으로 색상의 스펙트럼이 달라져서 그룹 자체를 나누는 게 시각적으로 보기에 편할 것 같네요.
이제 seaborn패키지에서 제공하는 heatmap으로 시각화를 해보겠습니다.
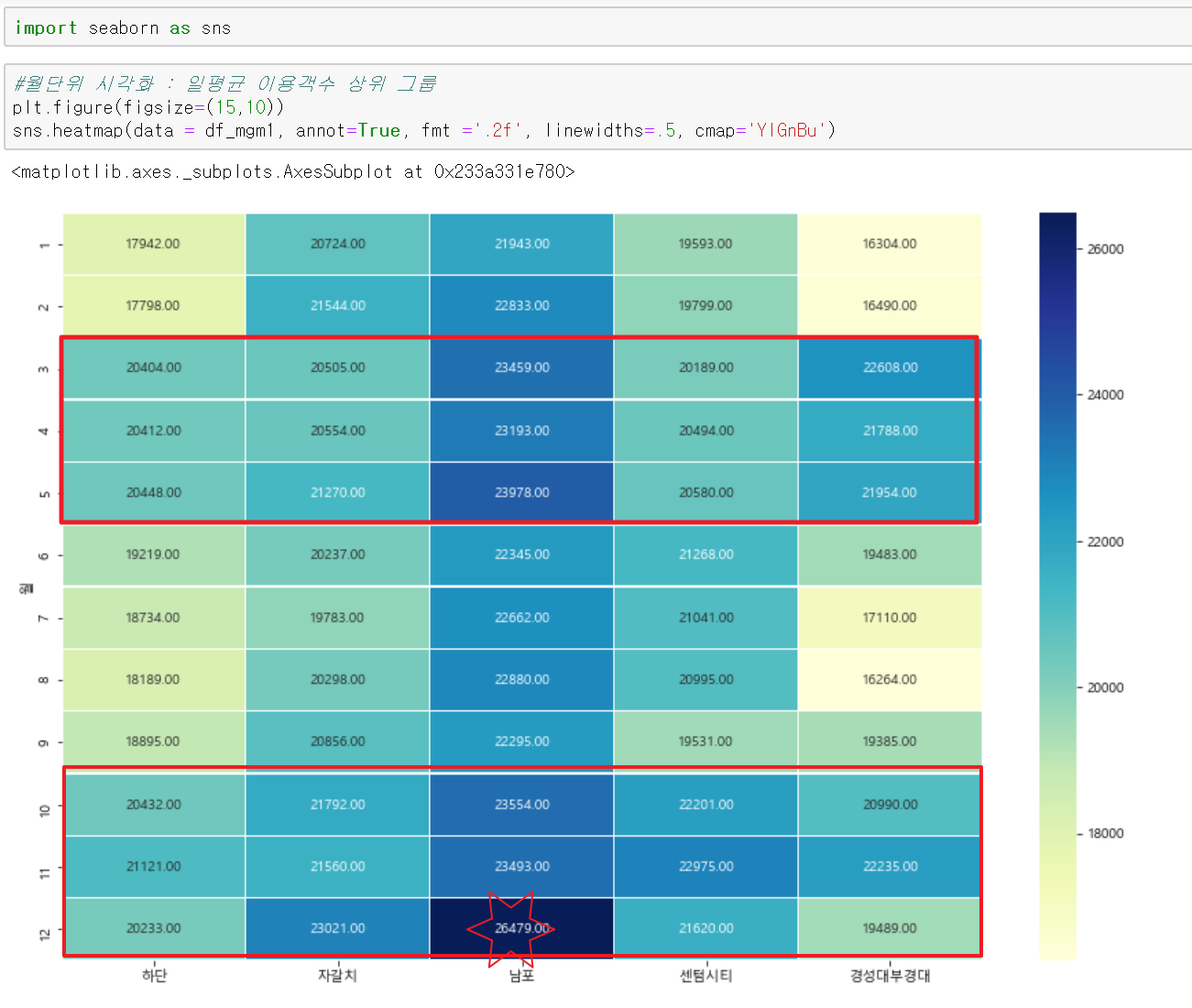
상위그룹에 해당하는 남포와 자갈치, 하단역을 보면 3,4,5월과 10,11,12월에 이용객이 많습니다. 특히 남포의 경우는 12월에 압도적으로 많은데 왜 그럴까요? 경성대부경대역은 주변 관광지로 가는 길이 용호동의 이기대쪽외에는 특별한 게 없는
데 비슷한 패턴으로 보이는데 이건 아무래도 대학가라 대학생들의 학기 중에 통학량이 많다고 추정이 가능할 수 있겠죠?
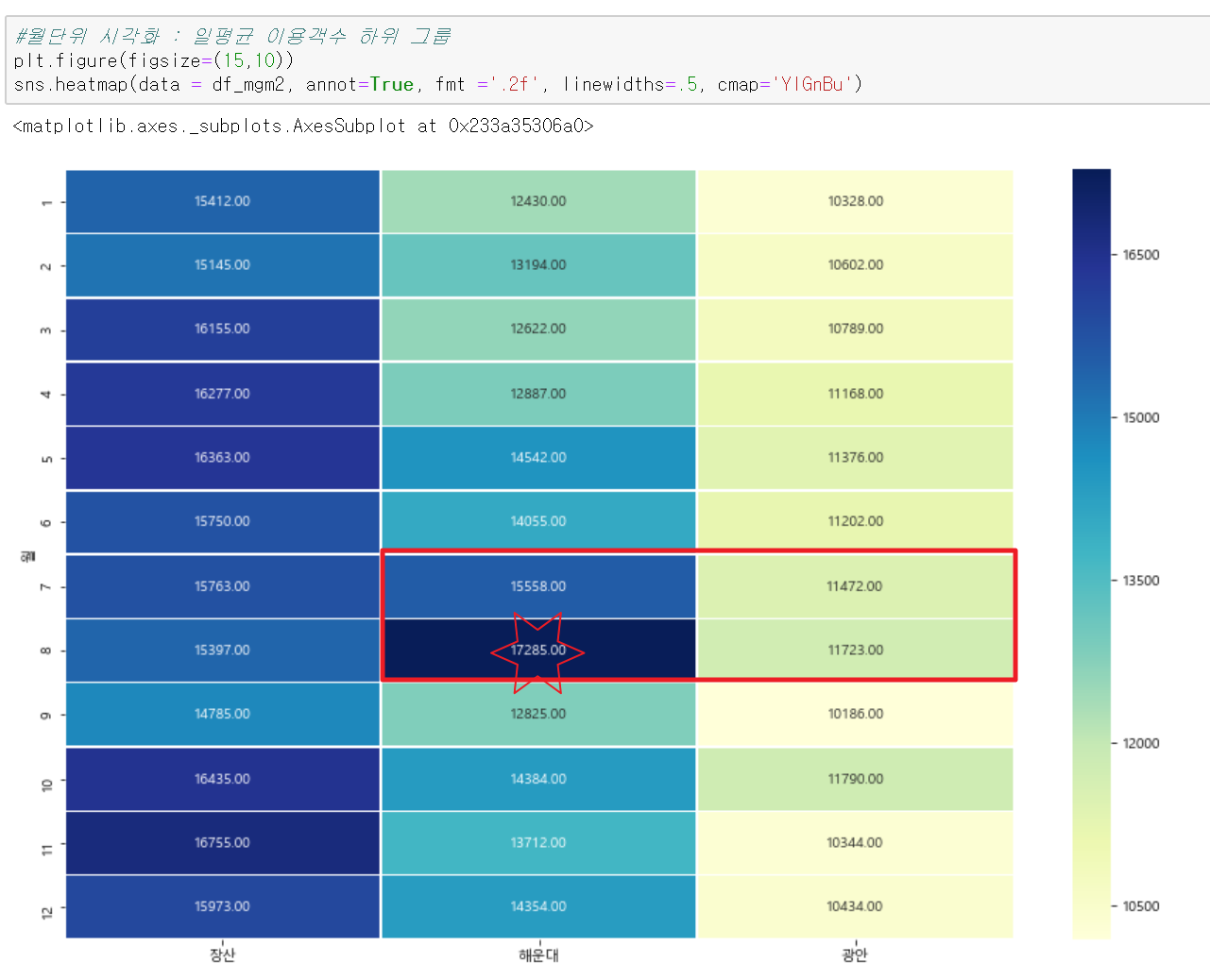
두 번째 그룹인 장산, 해운대, 광안을 보겠습니다. 장산의 경우는 신도시 주변 아파트 위주의 전형적인 베드타운 형태라 평균 이용객수가 크게 차이 나지 않고 꾸준하게 높아 보이고요. 해운대와 광안은 해수욕장을 낀 입지에 맞게 7,8월에 이용객수가 집중되는 경향을 보여줍니다.
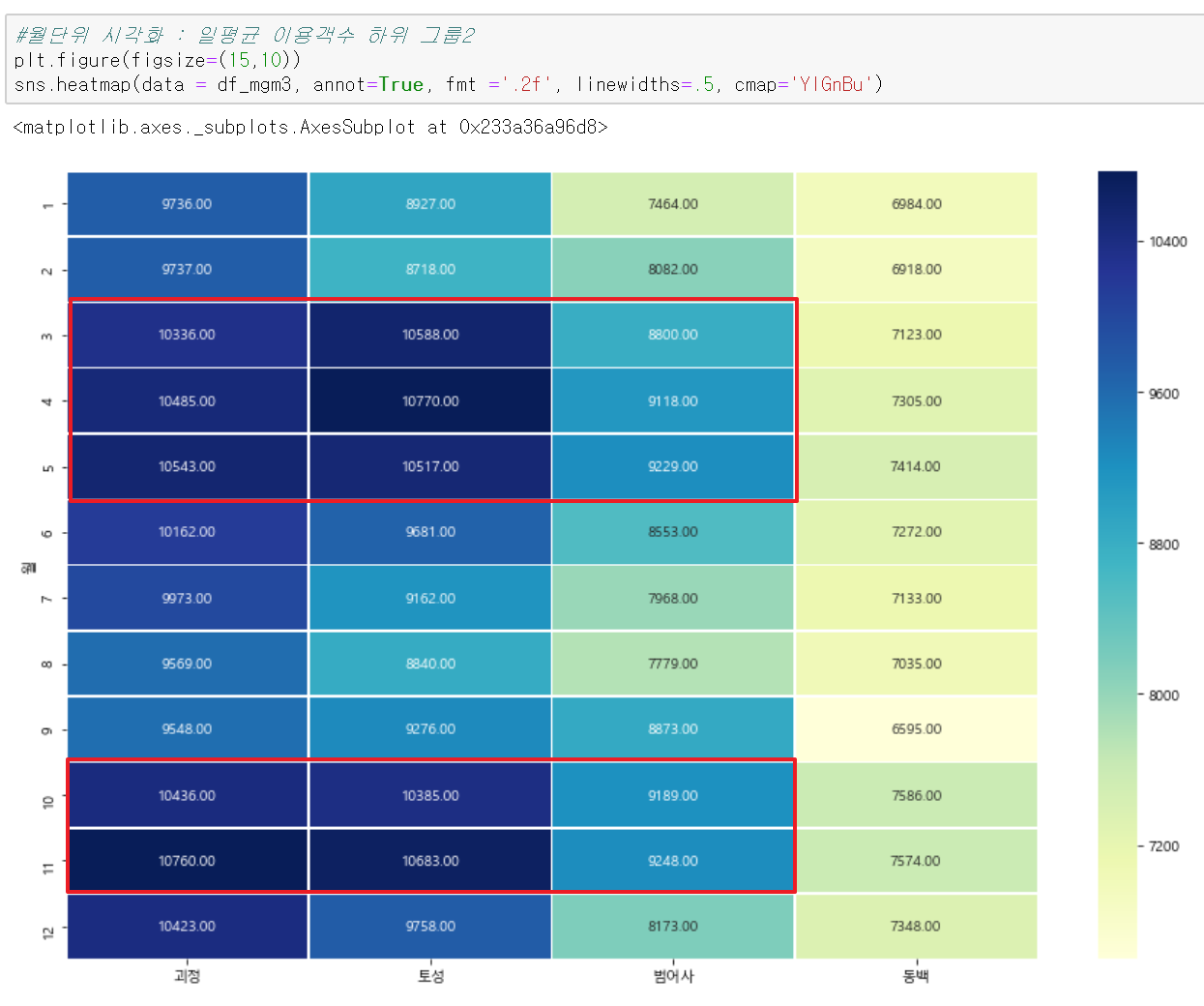
3번째 그룹인 괴정, 토성, 범어사를 살펴보겠습니다. 이역시 3,4,5월 10,11월에 이용객이 조금 더 집중되는 경향이 있네요.
첫 번째 그룹에서도 보는 것처럼 전통적인 관광지(해수욕장이 아닌)는 봄과 가을에 조금 이용객이 더 많아지는 것으로 보이네요. 역신 선선한 날씨가 일반 관광지에서는 중요하겠지요.
월 단위로 보면 조금 러프해서 주 단위로 한번 살펴보겠습니다.

첫 번째 그룹에서 남포역의 경우는 12월에서도 3~4주 차가 이용객이 압도적으로 많네요. 센텀시티의 경우는 46주 차에 가장 많은 이용객이 이용했고요. 경성대 부경대역의 경우는 방학기간에 이용객수가 확 줄어드는 모습이 보이시나요?
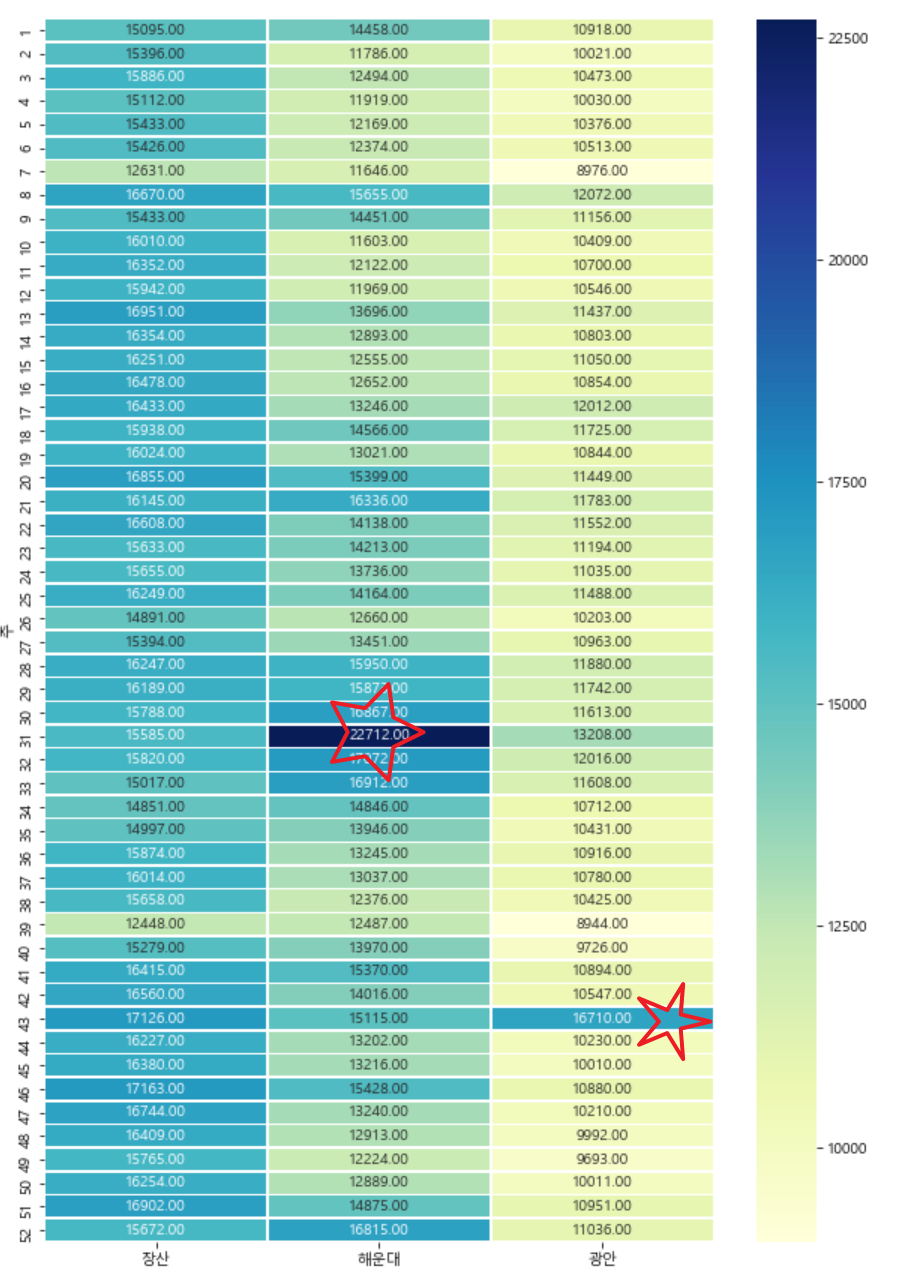
두 번째 그룹은 해운대의 경우 8월에 속한 31주 차 전후가 여름휴가철과 맞물려서 이용객이 많아 보이고요.
광안역의 경우 여름에도 이용객수가 조금 증가하고 그 밖에는 43주 차에 눈에 띄게 많은 이용객이 이용한 걸로 보입니다.
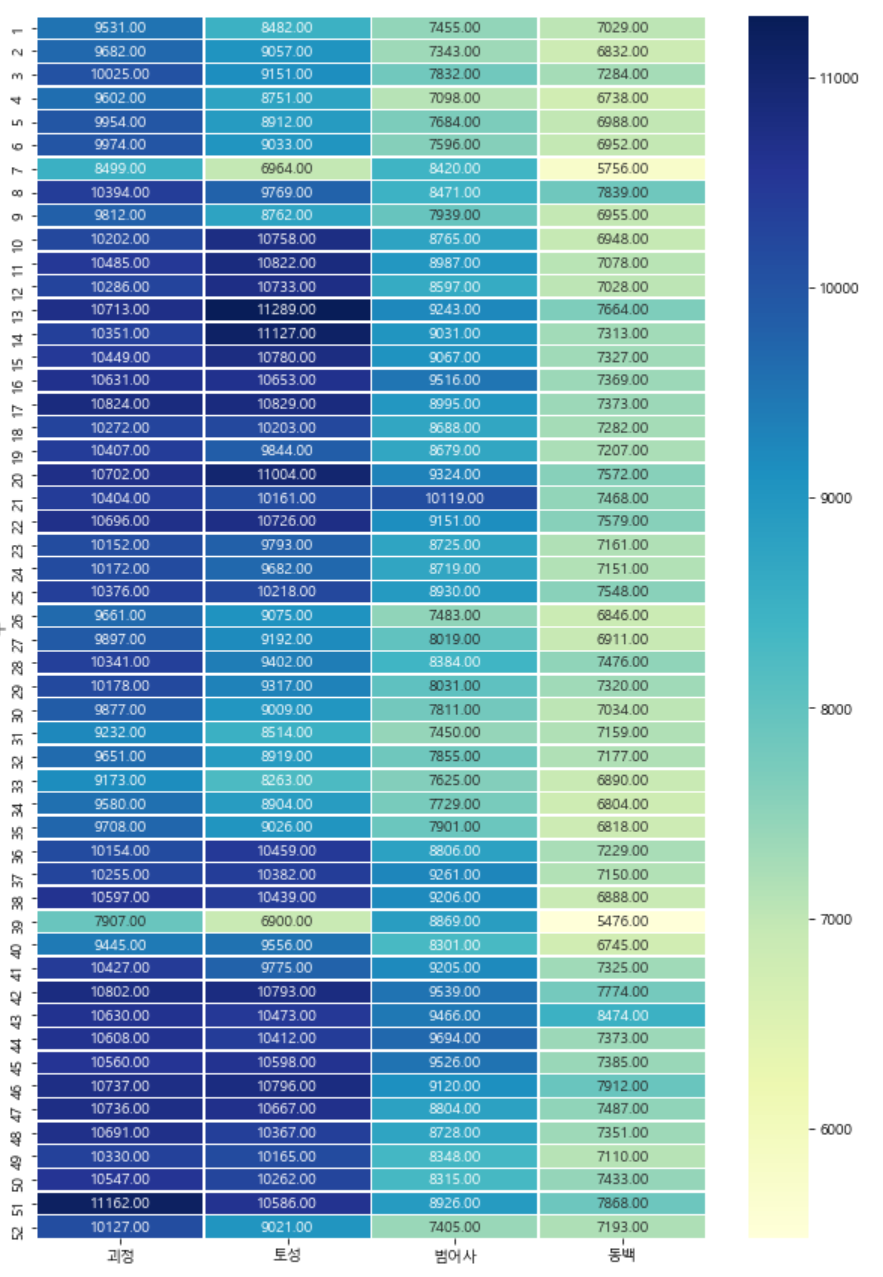
마지막 세 번째 그룹은 주별로 보니 오히려 동백역의 평균 이용객수가 적어서인지 패턴이 잘 보이지 않네요. 이경우는 개별로 히트맵을 따로 보면 그 역만의 특징이 쉽게 보일 수 있습니다 히트맵의 단점이기도 하겠네요.
마지막으로 요일별로 간단히 살펴보겠습니다. 이건 전체적으로본건데요 역시 주요 관광지가 인접한 역은 금,토 요일이 이용객수가 많은걸로 보이구요. 그외 지역은 주말보다는 역시 주중에 이용객이 조금 더 많은 패턴을 보이고 있네요.
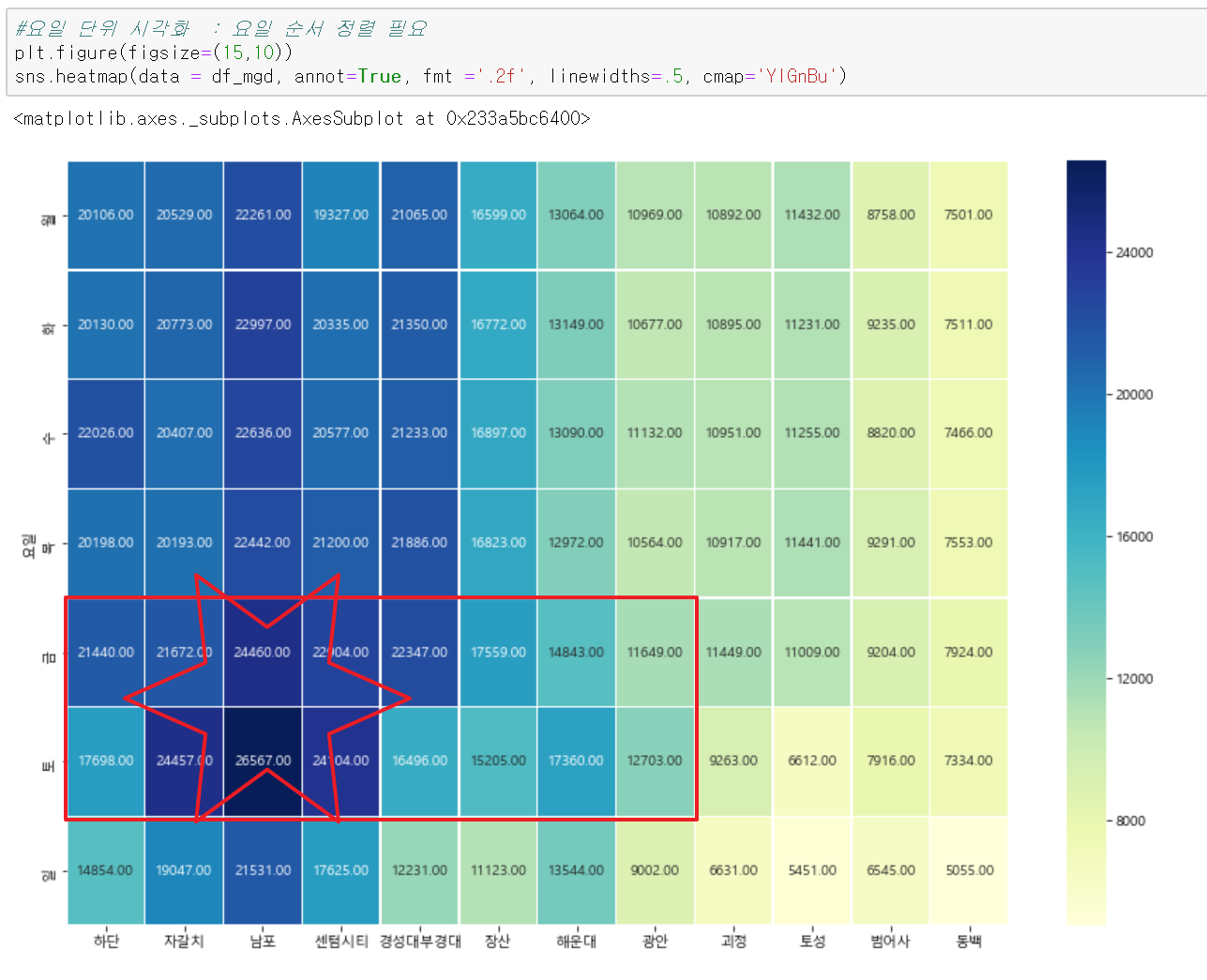
간단이 분석 결과를 요약해보면 아래 정도로 되겠네요. 부산의 경우는 일반 도시보다는 관광지로서의 특성이 강하게 나오는 편이라 관광객이 많은 기간에 지하철 이용객수에 대해서 적절한 대응을 해주면 좋겠지요?
- 해수욕장(여름휴가 성수기)이 아닌 전통적인 관광지가 있는 역들은 봄(3,4,5월)과 가을 초겨울(9,10,11,12월)에 이용객이 많다 (자갈치/남포/하단/괴정/토성/범어사)
- 여름휴가 기간(7~8월)에 이용객이 많은 곳은 해수욕장이 근접한 역이다 (해운대, 광안 )
- 광안역의 경우 10월에도 평균을 상회하였는데 박스 플롯 기준으로 아웃라이어 날짜는 5만 명이 넘게 이용한 날로 불꽃축제 날(10/27)로 확인된다.
- 같은 맥락으로 해운대의 아웃라이어(2만 명) 기준 날짜를 보면 해운대 모래축제(5/19~22) , 여름휴가 성수기(7/28~8/18), 지스타(11/17~18) 등 특별한 이벤트가 있는 날이다.
스크립트
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
import pandas as pd
#시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
#prj1에서 저장한 dfg2 엑셀파일 읽어오기
data= pd.read_excel('./data2/부산일자별도시철도이용객수.xlsx')
#열삭제
del data['Unnamed: 0']
data.info()
### 역번호를 주면 일자별 데이터프레임 리턴하는 함수를 만들어볼까?
def subway_df(n) :
df_f = data[data['역번호']== n] #함수용 데이터프레임을 변수에 해당하는값으로 만든다.
df_f=df_f.reset_index()
# 컬럼명을 기존 데이터프레임에서 가져와서 변경하려면 string형태로 가져와야 한다.
t=df_f.loc[:0,['역명']].max().values[0]
df_f=df_f[['년월일','이용객수']]
#컬럼명을 부산역으로 변경
df_f.columns = ['년월일',t]
return df_f
# 괴정/하단/토성/자갈치/남포/범어사
# 105/102/109/110/111/133/
# 장산/동백/센텀시티/해운대/광안/경성대부경대
# 201/204/206/203/209/212
df_105 = subway_df(105)
df_102 = subway_df(102)
df_109 = subway_df(109)
df_110 = subway_df(110)
df_111 = subway_df(111)
df_133 = subway_df(133)
df_201 = subway_df(201)
df_204 = subway_df(204)
df_206 = subway_df(206)
df_203 = subway_df(203)
df_209 = subway_df(209)
df_212 = subway_df(212)
#병합 1호선 병합
df_m1=pd.merge(pd.merge(pd.merge(pd.merge(pd.merge(df_105,df_102),df_109),df_110),df_111),df_133)
len(df_m1)
df_m2=pd.merge(pd.merge(pd.merge(pd.merge(pd.merge(df_201,df_204),df_206),df_203),df_209),df_212)
len(df_m2)
df_m = pd.merge(df_m1,df_m2)
##일자별로 보이기엔 데이터가 365개나 되서 많다. 주나 월단위로 해야 할것 같다.
df_m['월']=df_m['년월일'].dt.month
df_m.head()
#주 추가 하기
df_m['주'] =df_m['년월일'].apply(lambda x: x.weekofyear)
df_m.head()
#요일 반영하기
df_m['요일']= df_m['년월일'].dt.weekday.replace(0,'월').replace(1,'화').replace(2,'수').replace(3,'목').replace(4,'금').replace(5,'토').replace(6,'일')
df_m.head()
#주요역별로 box plot을 확인해볼까?
plt.figure(figsize=(15,10)) #크기지정
boxplot = df_m.boxplot(column=['괴정','하단','토성','자갈치','남포','범어사','장산','동백','센텀시티','해운대','광안','경성대부경대'])
plt.show()
df_mgm1 = round(df_m.groupby('월')[['하단','자갈치','남포','센텀시티','경성대부경대']].mean())
df_mgm2 = round(df_m.groupby('월')[['장산','해운대','광안']].mean())
df_mgm3 = round(df_m.groupby('월')[['괴정','토성','범어사','동백']].mean())
import seaborn as sns
#월단위 시각화 : 일평균 이용객수 상위 그룹
plt.figure(figsize=(15,10))
sns.heatmap(data = df_mgm1, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
#월단위 시각화 : 일평균 이용객수 하위 그룹
plt.figure(figsize=(15,10))
sns.heatmap(data = df_mgm2, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
#월단위 시각화 : 일평균 이용객수 하위 그룹2
plt.figure(figsize=(15,10))
sns.heatmap(data = df_mgm3, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
#주단위 이용객추이
#df_hgw = round(df_h.groupby('주')[['해운대']].mean())
df_mgw1 = round(df_m.groupby('주')[['하단','자갈치','남포','센텀시티','경성대부경대']].mean())
df_mgw2 = round(df_m.groupby('주')[['장산','해운대','광안']].mean())
df_mgw3 = round(df_m.groupby('주')[['괴정','토성','범어사','동백']].mean())
#52주단위 시각화
plt.figure(figsize=(10,15))
sns.heatmap(data = df_mgw1, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
#52주단위 시각화
plt.figure(figsize=(10,15))
sns.heatmap(data = df_mgw2, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
#52주단위 시각화
plt.figure(figsize=(10,15))
sns.heatmap(data = df_mgw3, annot=True, fmt ='.2f', linewidths=.5, cmap='YlGnBu')
|
cs |
'아재도 하는 데이터분석' 카테고리의 다른 글
| [데이터분석] 스타벅스 매장이 가장 많은 동네는? feat by R & QGIS (300원) (12) | 2019.11.12 |
|---|---|
| [250원] 데이터분석준전문가(ADsP) 자격증 시험후기 (0) | 2019.10.02 |
| [200원] Python 데이터분석 04 -데이터 시각화 (feat by folium) (2) | 2019.08.11 |
| [100원] Python 데이터분석 03 -데이터 프레임조작하기 (groupby) (0) | 2019.08.10 |
| [150원] Python 데이터분석 02 -데이터 정리 (4) | 2019.08.09 |