오늘은 지난번 포스팅에 이어 두 번째로 식품섭취량 조사 DB를 가지고 데이터 탐색을 해보겠습니다.
지난번 포스팅을 못 보신 분들은 먼저 보시면 됩니다.
[데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC)
들어가며 코로나-19(COVID-19) 사태로 대한민국에서 가장 바쁜신 분들이 바로 질병관리본부 직원들이지 않을까 싶습니다. (국민의 한사람으로서 이 자리를 빌어 감사의 인사를 전합니다.) 오늘은 ��
uincity.tistory.com
식품섭취조사(hn18_24rc) 데이터 탐색
DataExplorer 패키지로 살펴보기
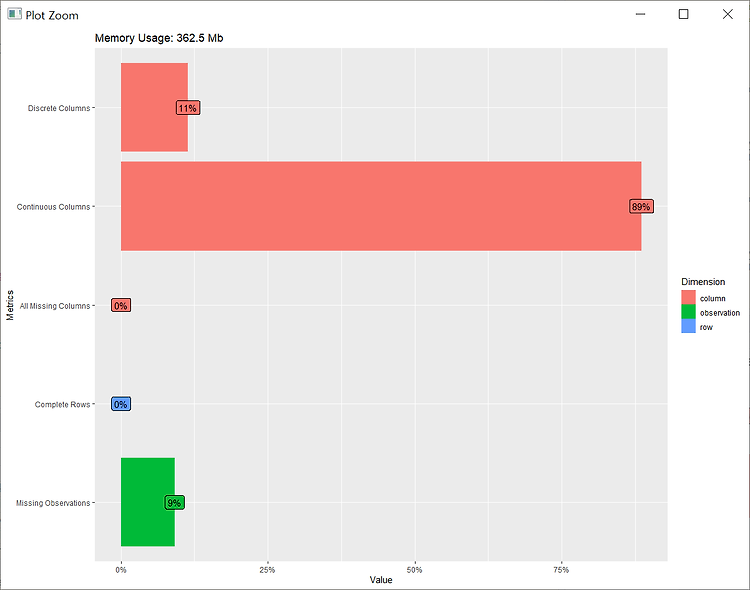
해당 파일은 509,819개의 데이터(rows)와 114개의 변수(columns)로 되어 있습니다.
|
1
2
|
> dim(df_hn18_24rc)
[1] 509819 114
|
cs |
앞서 소개한 DataExplorer 패키지의 introduce명령어로 간단히 살펴보겠습니다.
|
1
2
3
4
5
|
> introduce(df_hn18_24rc)
rows columns discrete_columns continuous_columns all_missing_columns total_missing_values complete_rows
1 509819 114 13 101 0 5298331 0
total_observations memory_usage
1 58119366 380151872
|
cs |
이산형 변수가 13개 연속형 변수가 101개로 확인이 됩니다. 데이터셋의 메모리 사용량은 50만 건이 넘어서인지 약 362MB의 용량을 차지하고 있습니다. plot_intro 명령으로 시각화를 해보면 다음과 같습니다.

이번에 plot_missing으로 결측치를 체크해보겠습니다.
기본 DB에 비해서는 변수의 수도 작고(?) 결측치가 없는 변수가 대부분으로 보입니다.
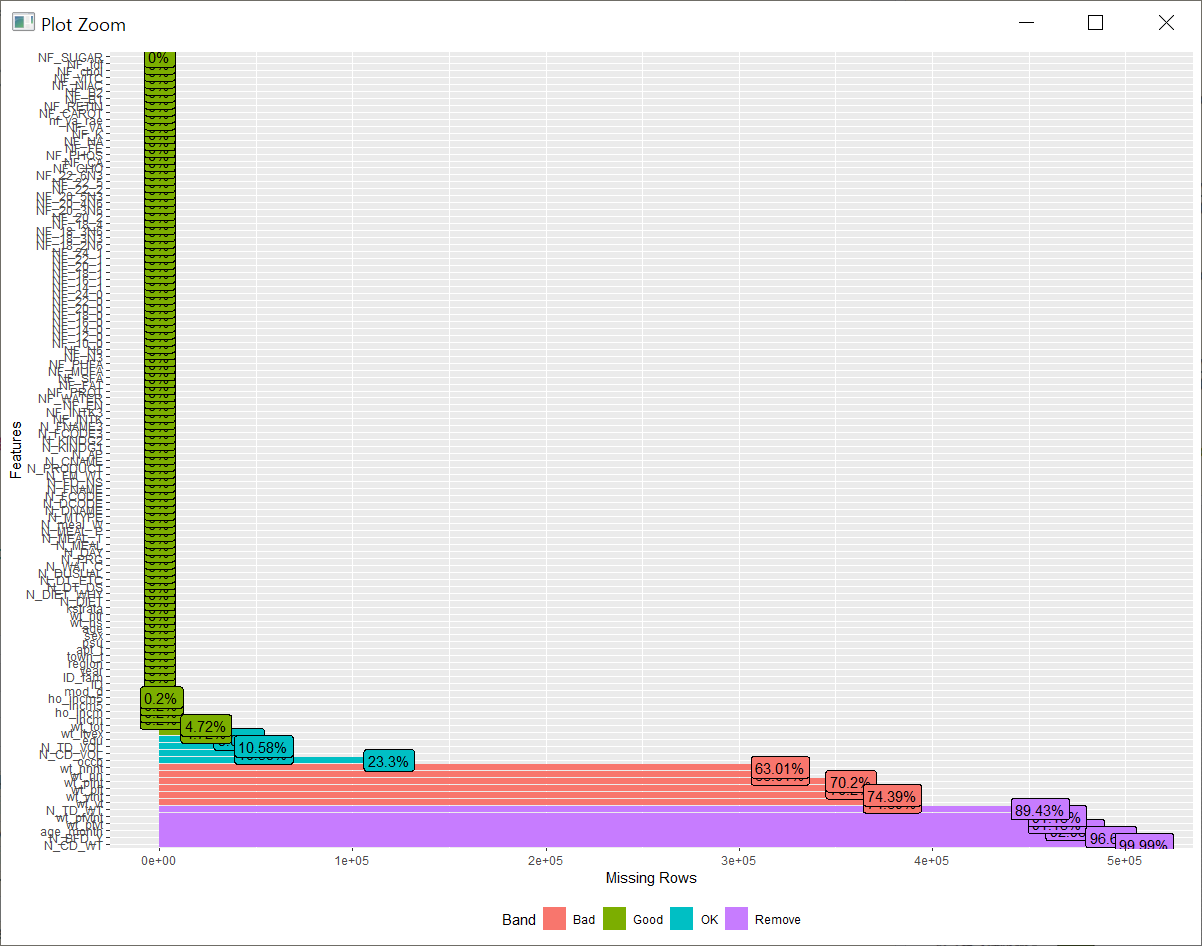
변수가 기본 DB에 비해서는 줄어들긴 했지만 역시 시각화를 통해서 보는 것으로는 한계가 있어 보이네요.
이럴 때 profile_missing 명령으로 데이터 프레임으로 만들어서 한번 살펴보겠습니다.
결측치가 1개 이상 있는 컬럼을 확인해보니 아래처럼 22개의 컬럼이 나옵니다. 확실이 기본 DB의 변수들보다는 결측치가 대부분 없는 변수들이 많습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
> #결측치 탐색
> df_hn18_24rc_missing <- profile_missing(df_hn18_24rc)
> #1개이상 결측치 존재 컬럼
> df_hn18_24rc_missing %>% filter(num_missing >1)
feature num_missing pct_missing
1 age_month 473903 0.92955147
2 incm 1020 0.00200071
3 ho_incm 1020 0.00200071
4 incm5 1020 0.00200071
5 ho_incm5 1020 0.00200071
6 edu 41138 0.08069138
7 occp 118799 0.23302192
8 wt_itvex 24079 0.04723049
9 wt_pft 357902 0.70201777
10 wt_vt 379278 0.74394638
11 wt_nn 321253 0.63013148
12 wt_tot 24079 0.04723049
13 wt_pfnt 357902 0.70201777
14 wt_pfvt 464693 0.91148623
15 wt_pfvtnt 464693 0.91148623
16 wt_vtnt 379278 0.74394638
17 wt_nnnt 321253 0.63013148
18 N_BFD_Y 492481 0.96599185
19 N_CD_VOL 53929 0.10578068
20 N_CD_WT 509747 0.99985877
21 N_TD_VOL 53929 0.10578068
22 N_TD_WT 455915 0.89426836
|
cs |
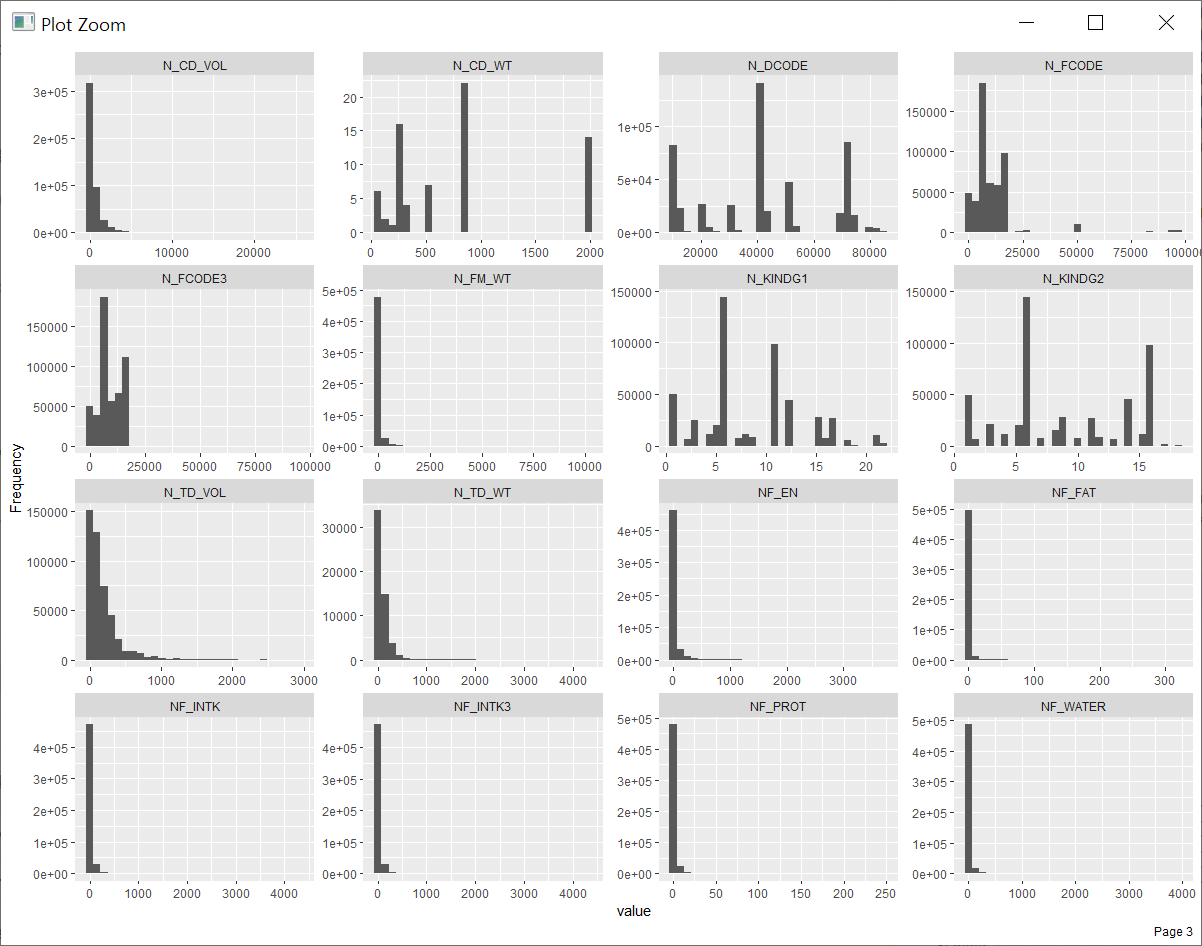
이산형인 경우는 plot_bar를 통해서 연속형 변수인 경우는 plot_histogram을 통해서 변수들의 분포를 시각화해서 확인해볼 수 있습니다. 앞서 introduce 명령으로 살펴본 것처럼 이산형 변수는 13개이고 연속형 변수가 101개라서 연속형 변수를 히스토그램으로 진행할 때 약간의 시간이 걸릴 수 있습니다.
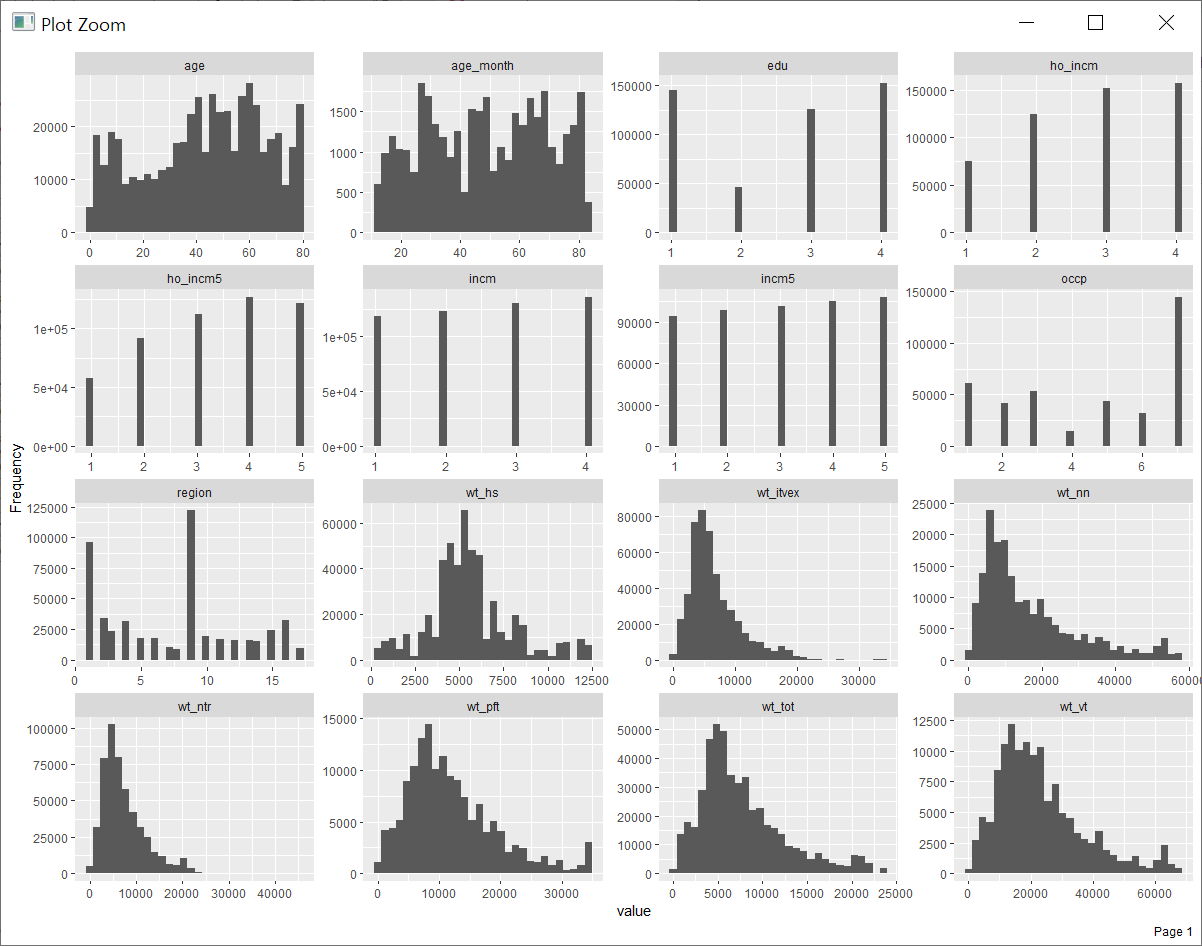
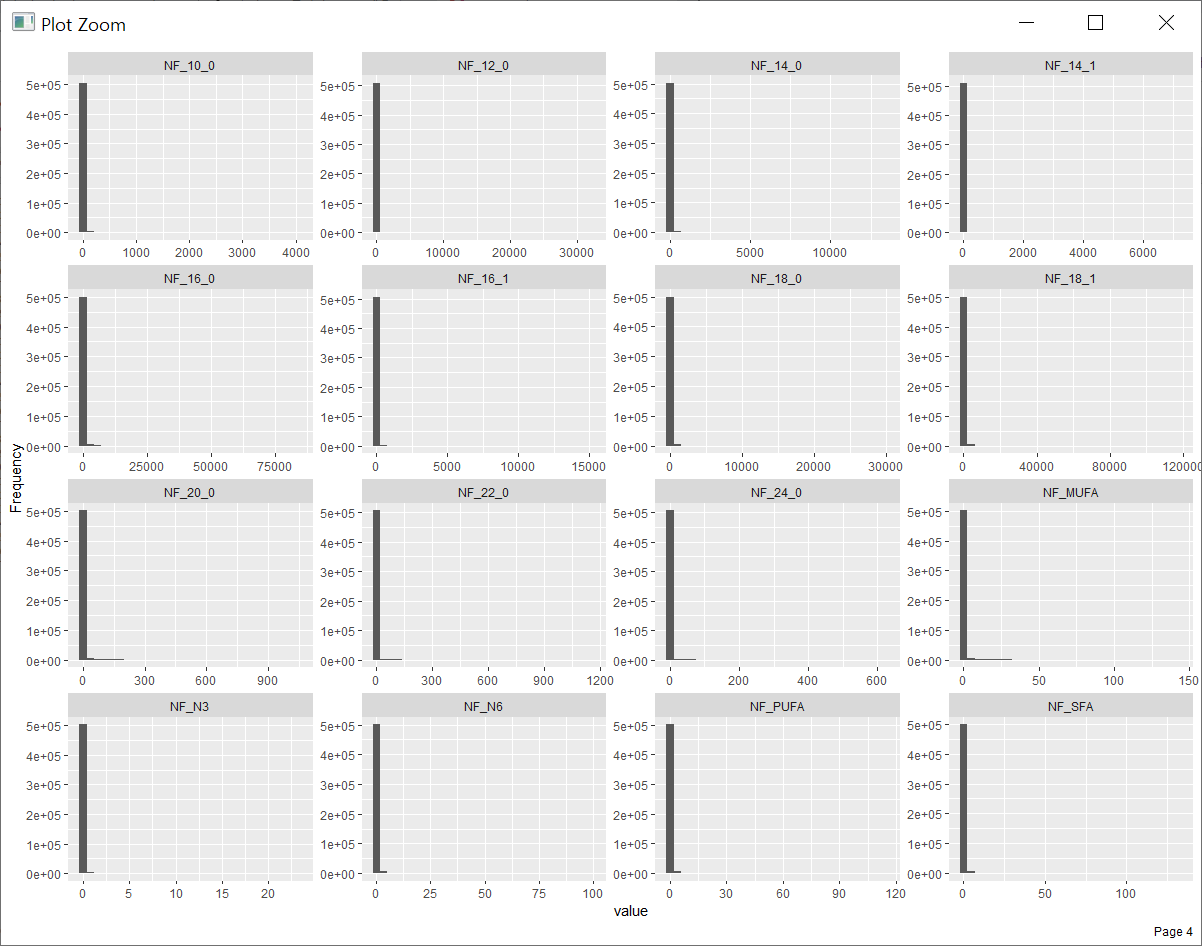
아래 연속형 변수들의 히스토그램을 보면 앞에 변수들은 그래도 분포가 골고루 나오는 반면에 뒤편의 변수들은 초반 숫자에 대부분 치중되어 있는 모습이 보입니다. 식품별 섭취량의 단위가 g과 mg 등 약간식 다른 상태이고 섭취량이 극단적으로 많은 경우가 대부분 있다는 것으로 보입니다.
 |
 |
 |
 |
 |
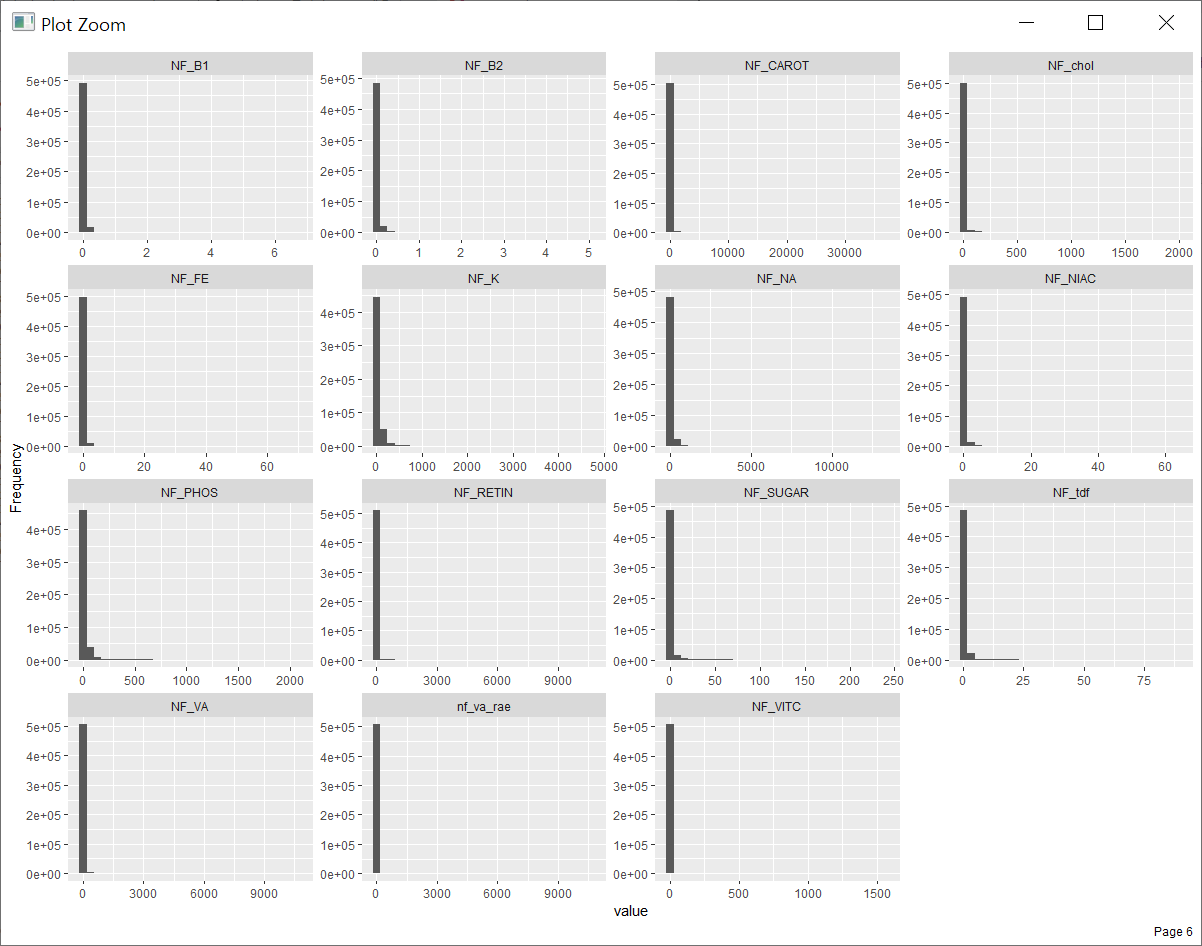 |
대표적으로 카프르 산(NF_10_0) 섭취량을 한번 살펴보면 전체 분포는 0~4000 (단위 mg)인데
섭취량이 100 이상인 건의 건수가 50만 건 중에 3700여 건 밖에 되지 않습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
df_hn18_24rc %>% filter(NF_10_0 >100) %>% select (ID,NF_10_0) %>% arrange(desc(NF_10_0)) %>% head(10)
ID NF_10_0
1 R904024302 4040.715
2 A914032303 2317.990
3 A914032304 2317.990
4 N910028801 1829.044
5 I905026903 1738.080
6 P904020604 1700.460
7 A902024002 1373.508
8 O908024901 1354.573
9 A914036104 1297.966
10 H924028002 1209.600
|
cs |
DataExploer 패키지에서는 이외에도 더 많은 기능들이 있는데요.
지금까지 봤던 것을 포함해서 보고서 형태로 요약해서 보여주는 create_report 펑션도 있으니 한번 사용해 보시기 바랍니다.
데이터 탐색(with dplyr)
이제 근본적으로 식품 섭취조사 데이터가 어떤 식으로 구성됐는지 세부 데이터를 한번 살펴보겠습니다.
이전 포스팅에서 국민건강 영양조사 2018년도의 경우 참여율을 살펴봤었는데 이 중에서 영양조사 참여 대상이 7069명이었습니다. 따라서 지금 살펴보는 식품 섭취조사는 이 7069명의 데이터로 구성되어 있다고 예측해볼 수 있습니다.
한번 ID 기준으로 데이터수를 카운팅 해보겠습니다. (dplyr 패키지를 사용했습니다)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
df_hn18_24rc %>% group_by(ID) %>% tally() -> df_id
dim(df_id)
[1] 7064 2
head(df_id)
# A tibble: 6 x 2
ID n
<fct> <int>
1 A901020501 41
2 A901021301 44
3 A901021302 69
4 A901023303 38
5 A901023304 38
6 A901023501 20
|
cs |
id기준으로 보닌 7064개의 ID가 나옵니다. 1개의 ID당 20여 개 이상의 여러 개의 데이터가 있는 것으로 보입니다.
|
1
2
3
4
5
6
7
8
9
|
summary(df_id)
ID n
A901020501: 1 Min. : 2.00
A901021301: 1 1st Qu.: 42.00
A901021302: 1 Median : 66.00
A901023303: 1 Mean : 72.17
A901023304: 1 3rd Qu.: 94.00
A901023501: 1 Max. :332.00
(Other) :7058
|
cs |
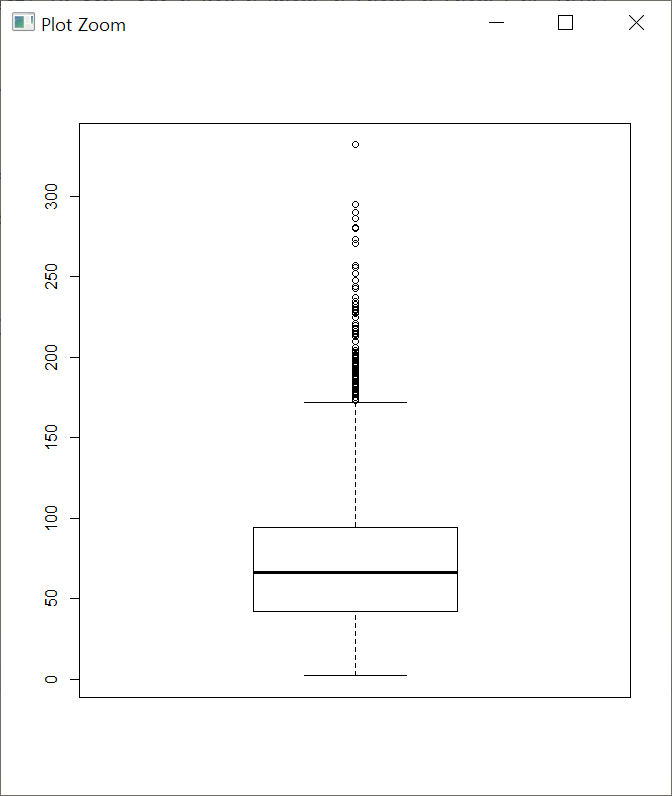
간단히 데이터수(n)에 대해서 상자 그림을 한번 보겠습니다. 평균이 72, 최댓값이 332개로 나타납니다.
즉 한 사람(ID) 별로 데이터수의 분포가 그렇다는 의미입니다.
데이터 갯 숫가 가장 많은 332개의 데이터를 가지고 있는 ID(D909030301)로 한번 심층적으로 살펴보겠습니다.
함께 제공되는 이용자 지침서에서 식품 섭취조사 부분을 살펴보니 N_MEAL이란 변수가 보입니다.
끼니 구분으로 되어 있고 1. 아침 2. 점심 3. 저녁 4. 간식 5. 식이보충제입니다.
해당 ID로 끼니 구분별로 카운팅을 해보니 이렇게 나옵니다.
|
1
2
3
4
5
6
7
8
9
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL) %>% tally()
# A tibble: 4 x 3
# Groups: ID [1]
ID N_MEAL n
<fct> <int> <int>
1 D909030301 1 10
2 D909030301 2 57
3 D909030301 3 263
4 D909030301 4 2
|
cs |
이분은 저녁(3) 때 뭔가 섭취 항목이 많은 걸 보니 많은 음식을 저녁에 드신 것 같습니다.
추가적으로 지침서상에 변수 중에 보니 음식명(N_DNAME)과 식품 코드명(N_FNAME)이란 변수가 확인됩니다.
해당 기준으로 다시 세분화해서 데이터수를 확인해보았습니다.
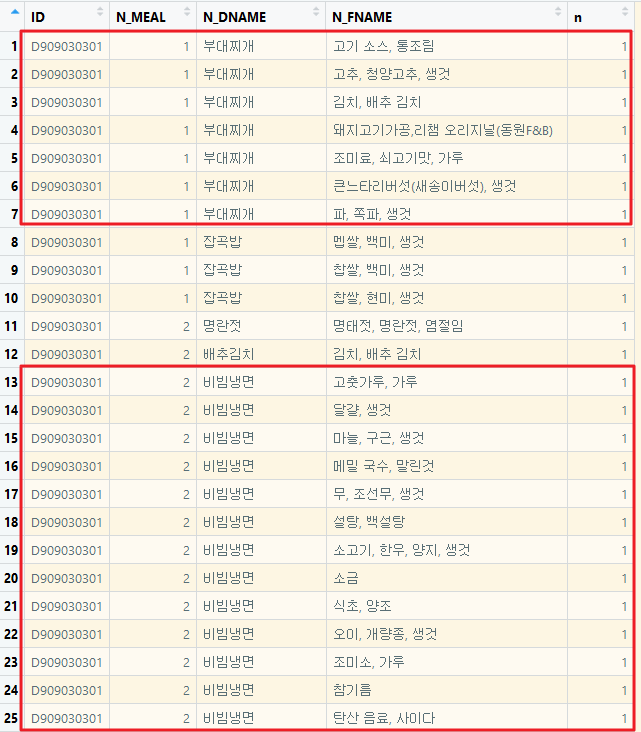
음식 기준으로 보니 아침(1) 식사는 부대찌개와 잡곡밥을 점심(2) 식사는 냉면과 밥을 함께 먹은 것 같습니다.
문제의 저녁(3)은 데이터가 다 확인 안 되지만 광어 초밥이 보이는 걸 보면 아무래도 뭔가 예상이 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_DNAME) %>%
tally() %>% arrange(N_MEAL) -> df_D909030301_d
df_D909030301_d
# A tibble: 33 x 4
# Groups: ID, N_MEAL [4]
ID N_MEAL N_DNAME n
<fct> <int> <fct> <int>
1 D909030301 1 부대찌개 7
2 D909030301 1 잡곡밥 3
3 D909030301 2 명란젓 1
4 D909030301 2 배추김치 1
5 D909030301 2 비빔냉면 13
6 D909030301 2 소세지어묵볶음 21
7 D909030301 2 잔멸치꽈리고추조림 18
8 D909030301 2 잡곡밥 3
9 D909030301 3 간장 1
10 D909030301 3 광어초밥 11
# ... with 23 more rows
|
cs |
궁금하니까 전체 데이터를 한번 보겠습니다.

역시 저녁 항목에 광어 초밥 외에 문어숙회, 생연어, 연어 초밥, 참치초밥, 캘리포니아롤, 크림 스파게티 까지?
아무래도 이분은 저녁은 해산물 뷔페에서 드신 것 같습니다. 데이터 빈도수로 캘리포니아롤과 스파게티가 좀 많아 보이는데 이 빈도가 결국 그걸 많이 먹었다는 의미는 아닐 수도 있습니다. 그래서 섭취한 식품 코드명까지 한번 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
> df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_DNAME,N_FNAME) %>%
+ tally() %>% arrange(N_MEAL)-> df_D909030301_f
> df_D909030301_f
# A tibble: 331 x 5
# Groups: ID, N_MEAL, N_DNAME [33]
ID N_MEAL N_DNAME N_FNAME n
<fct> <int> <fct> <fct> <int>
1 D909030301 1 부대찌개 고기 소스, 통조림 1
2 D909030301 1 부대찌개 고추, 청양고추, 생것 1
3 D909030301 1 부대찌개 김치, 배추 김치 1
4 D909030301 1 부대찌개 돼지고기가공,리챔 오리지널(동원F&B) 1
5 D909030301 1 부대찌개 조미료, 쇠고기맛, 가루 1
6 D909030301 1 부대찌개 큰느타리버섯(새송이버섯), 생것 1
7 D909030301 1 부대찌개 파, 쪽파, 생것 1
8 D909030301 1 잡곡밥 멥쌀, 백미, 생것 1
9 D909030301 1 잡곡밥 찹쌀, 백미, 생것 1
10 D909030301 1 잡곡밥 찹쌀, 현미, 생것 1
# ... with 321 more rows
|
cs |
자세히 살펴보기 위해서 음식별로 살펴보니 아래처럼 음식별로 구성된 식품이 하위분류가 식품명으로 되어 있네요 즉 그 음식을 구성하는 부가적인 재료(식품)를 분리해 놓았습니다.
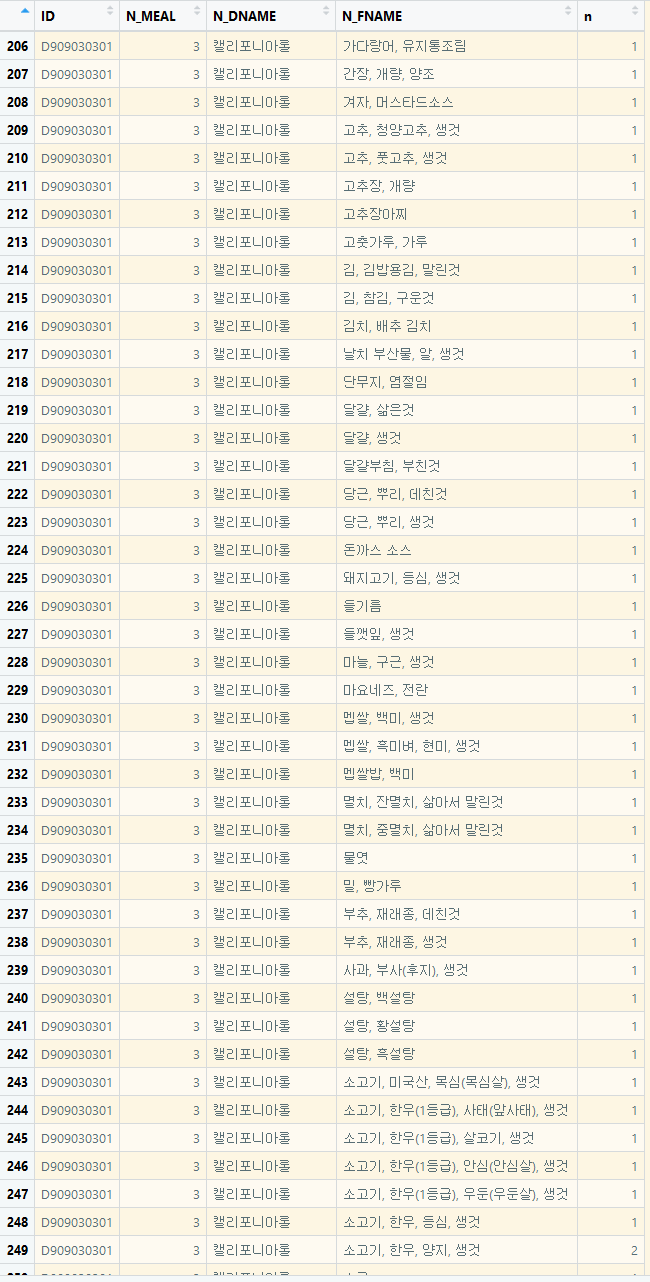
그럼 가장 많은 빈도를 보인 캘리포니아롤을 한번 보겠습니다. 아무래도 롤에 재료의 종류가 꽤 다양한가 봅니다.
롤을 구성하는 수많은 식품들이 나옵니다. 여기서 특이한 것은 비슷하지만 다른 식품으로 정의되어 있는 게 꽤 많다는 점입니다. 달걀의 경우도 삶은 달걀과 생달걀, 소고기의 경우도 부위별로 다 다르게 표시가 되어 있네요.
국민건강 영양조사의 영양섭취조사가 설문 형태로 진행되고 조사자가 설문을 할 때 전날 먹었던 저녁식사를 물었을 때 답변을 하는 사람은 그냥 캘리포니아롤 3개요~ 이렇게 대답했을 텐데 이게 데이터에는 이렇게 분리되어서 들어가 있네요~
그럼 궁극적으로 음식의 섭취량 부분을 한번 살펴보겠습니다. 식품명(N_FNAME) 기준으로 섭취량을 개별적으로 보게 되면 각 부분별로 결국 꽤 소량으로 보일듯합니다. 섭취량(NF_INTK)을 한번 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
> df_D909030301_intk %>% head(15)
ID N_MEAL N_DNAME N_FNAME NF_INTK
1 D909030301 3 캘리포니아롤 밀, 빵가루 0.0023360852
2 D909030301 3 캘리포니아롤 후추, 검은후추, 가루 0.0002625378
3 D909030301 3 캘리포니아롤 소금 0.0354167283
4 D909030301 3 캘리포니아롤 소금, 굵은소금 0.0001666599
5 D909030301 3 캘리포니아롤 조미료, 쇠고기맛, 가루 0.0005145871
6 D909030301 3 캘리포니아롤 겨자, 머스타드소스 0.0053733991
7 D909030301 3 캘리포니아롤 마요네즈, 전란 0.1611602944
8 D909030301 3 캘리포니아롤 돈까스 소스 0.0080704691
9 D909030301 3 캘리포니아롤 고추장, 개량 0.0043942804
10 D909030301 3 캘리포니아롤 고춧가루, 가루 0.0015594302
11 D909030301 3 캘리포니아롤 간장, 개량, 양조 0.0471246926
12 D909030301 3 캘리포니아롤 콩기름 0.0425762835
13 D909030301 3 캘리포니아롤 참기름 0.0861873348
14 D909030301 3 캘리포니아롤 올리브유 0.0004194558
15 D909030301 3 캘리포니아롤 옥수수기름 0.0094127088
|
cs |
역시 식품별로 보면 역시 후추나 소금 이런 건 미세한 양으로 섭취량이 되어 있습니다.
연구를 하시는 분들이 식품명 자체보다는 영양 관점에서 분석한다고 하면 식품이 아닌 식품군 분류(상위)로 필요할 것 같은데 이용자 지침서에 보면 역시 식품군 분류(N_KINDG1,2)라는 변수가 있습니다. 즉 이런 식품종류가 너무 많을 수 있으니 식품군 분류 값 기준으로 섭취량을 계산하는 게 연구하는데 훨씬 효율적이겠지요?
2018년도 데이터의 음식명과 식품명이 몇 개나 될지 한번 확인해볼까요?
음식명(N_DNAME)은 10,372개 식품명은(N_FNAME) 3,079개의 종류가 있네요.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
df_hn18_24rc %>% group_by(N_DNAME) %>% tally()
# A tibble: 10,372 x 2
N_DNAME n
<fct> <int>
1 ?지감자 3
2 ?파춥스 1
3 2%음료 1
4 2%음료,복숭아맛 1
5 2프로부족할때 1
6 3분미트볼 1
7 3분소고기간짜장 1
8 3분카레 2
9 ABC초콜렛 9
10 ABC초콜릿 1
# ... with 10,362 more rows
df_hn18_24rc %>% group_by(N_FNAME) %>% tally()
# A tibble: 3,079 x 2
N_FNAME n
<fct> <int>
1 가다랑어 육수 90
2 가다랑어, 반건 68
3 가다랑어, 유지통조림 348
4 가당음료,2%부족할때(롯데칠성음료) 2
5 가당음료,귀여운내친구뽀로로 딸기맛((주)팔도) 1
6 가당음료,귀여운내친구뽀로로 밀크맛(한국야쿠르트) 9
7 가당음료,썬키스트 레몬에이드(해태) 2
8 가당음료,파워오투 아이스베리((주)농심) 1
9 가당음료,파워오투 애플키위((주)농심) 3
10 가당음료,파워오투 오렌지레몬((주)농심) 3
# ... with 3,069 more rows
|
cs |
역시 분석을 효율적으로 하기 위해서는 식품군별로 보는 게 좋을 것 같은데 이용자 지침서에는 식품군이 2종류로 나옵니다. 분류방식이 식품군 분류 1(N_KINDG1)은 22가지로, 식품군 분류 2(N_KINDG2)는 18가지 종류로 나누어지네요
일단 해당 식품군별로 카운팅을 해보았습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
df_hn18_24rc %>% group_by(N_KINDG1) %>% tally()
# A tibble: 20 x 2
N_KINDG1 n
<int> <int>
1 1 50544
2 2 6459
3 3 24624
4 4 11303
5 5 20021
6 6 144233
7 7 7163
8 8 11465
9 9 8420
10 11 98239
11 12 44424
12 13 270
13 15 28326
14 16 7648
15 17 26718
16 18 6092
17 19 1024
18 20 47
19 21 10265
20 22 2534
df_hn18_24rc %>% group_by(N_KINDG2) %>% tally()
# A tibble: 18 x 2
N_KINDG2 n
<int> <int>
1 1 49379
2 2 6478
3 3 21609
4 4 11303
5 5 20021
6 6 144627
7 7 7163
8 8 14946
9 9 28114
10 10 7648
11 11 26715
12 12 8419
13 13 6146
14 14 45394
15 15 11905
16 16 97812
17 17 1472
18 18 668
|
cs |
마지막으로 데이터 건수가 가장 많은 이분이 하루 동안 가장 많이 먹은 음식을 한번 살펴보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_KINDG1) %>%
summarise(sum(NF_INTK)) ->df_D909030301_sum
colnames(df_D909030301_sum) <- c(names(df_D909030301_sum)[1:3],"sum_intk")
df_D909030301_sum %>% arrange(desc(sum_intk))
# A tibble: 33 x 4
# Groups: ID, N_MEAL [4]
ID N_MEAL N_KINDG1 sum_intk
<fct> <int> <int> <dbl>
1 D909030301 3 21 501.
2 D909030301 3 18 324.
3 D909030301 2 1 275.
4 D909030301 1 1 186.
5 D909030301 4 21 168
6 D909030301 3 17 153.
7 D909030301 3 1 93.1
8 D909030301 3 8 81.7
9 D909030301 2 6 55.0
10 D909030301 1 7 44.9
# ... with 23 more rows
|
cs |
가장 많은 섭취량은 저녁(3) 식사시간에 501g을 섭취한 음료(21) 324g을 섭취한 우유류(18)이네요.
해산물 뷔페에 갔지만 생각보다 초밥류를 많이 먹지는 않은듯합니다. 3위가 점심(2) 때 먹은 곡류(1)이고 4위가 아침(1)에 먹은 곡류(1)입니다. 5위는 간식(4)에 포함된 또 음료(21)입니다. 6위에서 보면 153g으로 저녁(3)에 어패류(17) 항목이 보이네요. 이분은 생각보다 음료수 섭취량이 많으신 분이네요.
하지만 뷔페를 갔는데 끼니별 섭취량을 한번 다시 합산해보겠습니다.
역시 저녁(3)이 1223g으로 가장 양이 많네요. 이것이 바로 뷔페의 힘(?)이겠죠.(농담입니다)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
> #끼니별 섭취량
> df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL) %>%
+ summarise(sum(NF_INTK)) -> df_D909030301_sum2
> colnames(df_D909030301_sum2) <- c(names(df_D909030301_sum2)[1:2],"sum_intk")
> df_D909030301_sum2 %>% arrange(desc(sum_intk))
# A tibble: 4 x 3
# Groups: ID [1]
ID N_MEAL sum_intk
<fct> <int> <dbl>
1 D909030301 3 1223.
2 D909030301 2 424.
3 D909030301 1 333.
4 D909030301 4 168
|
cs |
마무리
이상으로 국민건강 영양조사에서 식품섭취량 DB파일을 살펴보았습니다. 데이터셋이 어떤 식의 구조이고 어떻게 데이터를 담고 있는지는 변수와 여러 집계 함수를 이용해서 파악을 해보아야 합니다.
이전 포스팅에서는 기본 DB의 구조를 살짝 보긴 했는데 이번처럼 자세히 보지는 못했던 것 같네요.
이런 구조로 되어 있다는 걸 파악을 했으니 다음번에는 해당 데이터셋의 이상치(Outlier)를 찾는 방법을 함께 고민해보겠습니다.
함께보면 좋을 글
Introduction to DataExplorer
This document introduces the package DataExplorer, and shows how it can help you with different tasks throughout your data exploration process. The remaining of this guide will be organized in accordance with the goals. As the package evolves, more content
cran.r-project.org
R for Data Science
This book will teach you how to do data science with R: You’ll learn how to get your data into R, get it into the most useful structure, transform it, visualise it and model it. In this book, you will find a practicum of skills for data science. Just as
r4ds.had.co.nz
[DataMining] 2. 시각화를 통한 탐색적 데이터 분석(EDA)
데이터 시각화를 통한 탐색적 데이터 분석 탐색적 데이터 분석이란? 데이터에 대한 질문을 찾는다. 데이터에 대한 시각화, 변환, 모델링으로 답을 찾는다. 답을 통해 질문을 심화하고 새로운 질�
jtoday.tistory.com
'아재도 하는 데이터분석' 카테고리의 다른 글
| "[부산 아파트 가격 예측 1편] 2020-2024 부산 남구 실거래 데이터 분석 및 시각화" (0) | 2024.12.25 |
|---|---|
| [데이터소개] 스타벅스 매장은 지난 1년간 얼마나 늘었을까?(feat. 스타벅스 매장 목록 파일, 2023.06.15.) (1) | 2023.06.17 |
| [데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC) (0) | 2020.05.19 |
| [데이터분석] 한우 사육현황 데이터 시각화 feat by ggplot2 & Excel (2) | 2020.05.16 |
| [데이터분석] 일자리가 가장 많은 동네는?(feat by 국세통계 연말정산 신고현황) (0) | 2020.03.11 |
오늘은 지난번 포스팅에 이어 두 번째로 식품섭취량 조사 DB를 가지고 데이터 탐색을 해보겠습니다.
지난번 포스팅을 못 보신 분들은 먼저 보시면 됩니다.
[데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC)
들어가며 코로나-19(COVID-19) 사태로 대한민국에서 가장 바쁜신 분들이 바로 질병관리본부 직원들이지 않을까 싶습니다. (국민의 한사람으로서 이 자리를 빌어 감사의 인사를 전합니다.) 오늘은 ��
uincity.tistory.com
식품섭취조사(hn18_24rc) 데이터 탐색
DataExplorer 패키지로 살펴보기
해당 파일은 509,819개의 데이터(rows)와 114개의 변수(columns)로 되어 있습니다.
|
1
2
|
> dim(df_hn18_24rc)
[1] 509819 114
|
cs |
앞서 소개한 DataExplorer 패키지의 introduce명령어로 간단히 살펴보겠습니다.
|
1
2
3
4
5
|
> introduce(df_hn18_24rc)
rows columns discrete_columns continuous_columns all_missing_columns total_missing_values complete_rows
1 509819 114 13 101 0 5298331 0
total_observations memory_usage
1 58119366 380151872
|
cs |
이산형 변수가 13개 연속형 변수가 101개로 확인이 됩니다. 데이터셋의 메모리 사용량은 50만 건이 넘어서인지 약 362MB의 용량을 차지하고 있습니다. plot_intro 명령으로 시각화를 해보면 다음과 같습니다.
이번에 plot_missing으로 결측치를 체크해보겠습니다.
기본 DB에 비해서는 변수의 수도 작고(?) 결측치가 없는 변수가 대부분으로 보입니다.
변수가 기본 DB에 비해서는 줄어들긴 했지만 역시 시각화를 통해서 보는 것으로는 한계가 있어 보이네요.
이럴 때 profile_missing 명령으로 데이터 프레임으로 만들어서 한번 살펴보겠습니다.
결측치가 1개 이상 있는 컬럼을 확인해보니 아래처럼 22개의 컬럼이 나옵니다. 확실이 기본 DB의 변수들보다는 결측치가 대부분 없는 변수들이 많습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
> #결측치 탐색
> df_hn18_24rc_missing <- profile_missing(df_hn18_24rc)
> #1개이상 결측치 존재 컬럼
> df_hn18_24rc_missing %>% filter(num_missing >1)
feature num_missing pct_missing
1 age_month 473903 0.92955147
2 incm 1020 0.00200071
3 ho_incm 1020 0.00200071
4 incm5 1020 0.00200071
5 ho_incm5 1020 0.00200071
6 edu 41138 0.08069138
7 occp 118799 0.23302192
8 wt_itvex 24079 0.04723049
9 wt_pft 357902 0.70201777
10 wt_vt 379278 0.74394638
11 wt_nn 321253 0.63013148
12 wt_tot 24079 0.04723049
13 wt_pfnt 357902 0.70201777
14 wt_pfvt 464693 0.91148623
15 wt_pfvtnt 464693 0.91148623
16 wt_vtnt 379278 0.74394638
17 wt_nnnt 321253 0.63013148
18 N_BFD_Y 492481 0.96599185
19 N_CD_VOL 53929 0.10578068
20 N_CD_WT 509747 0.99985877
21 N_TD_VOL 53929 0.10578068
22 N_TD_WT 455915 0.89426836
|
cs |
이산형인 경우는 plot_bar를 통해서 연속형 변수인 경우는 plot_histogram을 통해서 변수들의 분포를 시각화해서 확인해볼 수 있습니다. 앞서 introduce 명령으로 살펴본 것처럼 이산형 변수는 13개이고 연속형 변수가 101개라서 연속형 변수를 히스토그램으로 진행할 때 약간의 시간이 걸릴 수 있습니다.
아래 연속형 변수들의 히스토그램을 보면 앞에 변수들은 그래도 분포가 골고루 나오는 반면에 뒤편의 변수들은 초반 숫자에 대부분 치중되어 있는 모습이 보입니다. 식품별 섭취량의 단위가 g과 mg 등 약간식 다른 상태이고 섭취량이 극단적으로 많은 경우가 대부분 있다는 것으로 보입니다.
|
|
|
|
|
|
대표적으로 카프르 산(NF_10_0) 섭취량을 한번 살펴보면 전체 분포는 0~4000 (단위 mg)인데
섭취량이 100 이상인 건의 건수가 50만 건 중에 3700여 건 밖에 되지 않습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
df_hn18_24rc %>% filter(NF_10_0 >100) %>% select (ID,NF_10_0) %>% arrange(desc(NF_10_0)) %>% head(10)
ID NF_10_0
1 R904024302 4040.715
2 A914032303 2317.990
3 A914032304 2317.990
4 N910028801 1829.044
5 I905026903 1738.080
6 P904020604 1700.460
7 A902024002 1373.508
8 O908024901 1354.573
9 A914036104 1297.966
10 H924028002 1209.600
|
cs |
DataExploer 패키지에서는 이외에도 더 많은 기능들이 있는데요.
지금까지 봤던 것을 포함해서 보고서 형태로 요약해서 보여주는 create_report 펑션도 있으니 한번 사용해 보시기 바랍니다.
데이터 탐색(with dplyr)
이제 근본적으로 식품 섭취조사 데이터가 어떤 식으로 구성됐는지 세부 데이터를 한번 살펴보겠습니다.
이전 포스팅에서 국민건강 영양조사 2018년도의 경우 참여율을 살펴봤었는데 이 중에서 영양조사 참여 대상이 7069명이었습니다. 따라서 지금 살펴보는 식품 섭취조사는 이 7069명의 데이터로 구성되어 있다고 예측해볼 수 있습니다.
한번 ID 기준으로 데이터수를 카운팅 해보겠습니다. (dplyr 패키지를 사용했습니다)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
df_hn18_24rc %>% group_by(ID) %>% tally() -> df_id
dim(df_id)
[1] 7064 2
head(df_id)
# A tibble: 6 x 2
ID n
<fct> <int>
1 A901020501 41
2 A901021301 44
3 A901021302 69
4 A901023303 38
5 A901023304 38
6 A901023501 20
|
cs |
id기준으로 보닌 7064개의 ID가 나옵니다. 1개의 ID당 20여 개 이상의 여러 개의 데이터가 있는 것으로 보입니다.
|
1
2
3
4
5
6
7
8
9
|
summary(df_id)
ID n
A901020501: 1 Min. : 2.00
A901021301: 1 1st Qu.: 42.00
A901021302: 1 Median : 66.00
A901023303: 1 Mean : 72.17
A901023304: 1 3rd Qu.: 94.00
A901023501: 1 Max. :332.00
(Other) :7058
|
cs |
간단히 데이터수(n)에 대해서 상자 그림을 한번 보겠습니다. 평균이 72, 최댓값이 332개로 나타납니다.
즉 한 사람(ID) 별로 데이터수의 분포가 그렇다는 의미입니다.
데이터 갯 숫가 가장 많은 332개의 데이터를 가지고 있는 ID(D909030301)로 한번 심층적으로 살펴보겠습니다.
함께 제공되는 이용자 지침서에서 식품 섭취조사 부분을 살펴보니 N_MEAL이란 변수가 보입니다.
끼니 구분으로 되어 있고 1. 아침 2. 점심 3. 저녁 4. 간식 5. 식이보충제입니다.
해당 ID로 끼니 구분별로 카운팅을 해보니 이렇게 나옵니다.
|
1
2
3
4
5
6
7
8
9
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL) %>% tally()
# A tibble: 4 x 3
# Groups: ID [1]
ID N_MEAL n
<fct> <int> <int>
1 D909030301 1 10
2 D909030301 2 57
3 D909030301 3 263
4 D909030301 4 2
|
cs |
이분은 저녁(3) 때 뭔가 섭취 항목이 많은 걸 보니 많은 음식을 저녁에 드신 것 같습니다.
추가적으로 지침서상에 변수 중에 보니 음식명(N_DNAME)과 식품 코드명(N_FNAME)이란 변수가 확인됩니다.
해당 기준으로 다시 세분화해서 데이터수를 확인해보았습니다.
음식 기준으로 보니 아침(1) 식사는 부대찌개와 잡곡밥을 점심(2) 식사는 냉면과 밥을 함께 먹은 것 같습니다.
문제의 저녁(3)은 데이터가 다 확인 안 되지만 광어 초밥이 보이는 걸 보면 아무래도 뭔가 예상이 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_DNAME) %>%
tally() %>% arrange(N_MEAL) -> df_D909030301_d
df_D909030301_d
# A tibble: 33 x 4
# Groups: ID, N_MEAL [4]
ID N_MEAL N_DNAME n
<fct> <int> <fct> <int>
1 D909030301 1 부대찌개 7
2 D909030301 1 잡곡밥 3
3 D909030301 2 명란젓 1
4 D909030301 2 배추김치 1
5 D909030301 2 비빔냉면 13
6 D909030301 2 소세지어묵볶음 21
7 D909030301 2 잔멸치꽈리고추조림 18
8 D909030301 2 잡곡밥 3
9 D909030301 3 간장 1
10 D909030301 3 광어초밥 11
# ... with 23 more rows
|
cs |
궁금하니까 전체 데이터를 한번 보겠습니다.
역시 저녁 항목에 광어 초밥 외에 문어숙회, 생연어, 연어 초밥, 참치초밥, 캘리포니아롤, 크림 스파게티 까지?
아무래도 이분은 저녁은 해산물 뷔페에서 드신 것 같습니다. 데이터 빈도수로 캘리포니아롤과 스파게티가 좀 많아 보이는데 이 빈도가 결국 그걸 많이 먹었다는 의미는 아닐 수도 있습니다. 그래서 섭취한 식품 코드명까지 한번 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
> df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_DNAME,N_FNAME) %>%
+ tally() %>% arrange(N_MEAL)-> df_D909030301_f
> df_D909030301_f
# A tibble: 331 x 5
# Groups: ID, N_MEAL, N_DNAME [33]
ID N_MEAL N_DNAME N_FNAME n
<fct> <int> <fct> <fct> <int>
1 D909030301 1 부대찌개 고기 소스, 통조림 1
2 D909030301 1 부대찌개 고추, 청양고추, 생것 1
3 D909030301 1 부대찌개 김치, 배추 김치 1
4 D909030301 1 부대찌개 돼지고기가공,리챔 오리지널(동원F&B) 1
5 D909030301 1 부대찌개 조미료, 쇠고기맛, 가루 1
6 D909030301 1 부대찌개 큰느타리버섯(새송이버섯), 생것 1
7 D909030301 1 부대찌개 파, 쪽파, 생것 1
8 D909030301 1 잡곡밥 멥쌀, 백미, 생것 1
9 D909030301 1 잡곡밥 찹쌀, 백미, 생것 1
10 D909030301 1 잡곡밥 찹쌀, 현미, 생것 1
# ... with 321 more rows
|
cs |
자세히 살펴보기 위해서 음식별로 살펴보니 아래처럼 음식별로 구성된 식품이 하위분류가 식품명으로 되어 있네요 즉 그 음식을 구성하는 부가적인 재료(식품)를 분리해 놓았습니다.
그럼 가장 많은 빈도를 보인 캘리포니아롤을 한번 보겠습니다. 아무래도 롤에 재료의 종류가 꽤 다양한가 봅니다.
롤을 구성하는 수많은 식품들이 나옵니다. 여기서 특이한 것은 비슷하지만 다른 식품으로 정의되어 있는 게 꽤 많다는 점입니다. 달걀의 경우도 삶은 달걀과 생달걀, 소고기의 경우도 부위별로 다 다르게 표시가 되어 있네요.
국민건강 영양조사의 영양섭취조사가 설문 형태로 진행되고 조사자가 설문을 할 때 전날 먹었던 저녁식사를 물었을 때 답변을 하는 사람은 그냥 캘리포니아롤 3개요~ 이렇게 대답했을 텐데 이게 데이터에는 이렇게 분리되어서 들어가 있네요~
그럼 궁극적으로 음식의 섭취량 부분을 한번 살펴보겠습니다. 식품명(N_FNAME) 기준으로 섭취량을 개별적으로 보게 되면 각 부분별로 결국 꽤 소량으로 보일듯합니다. 섭취량(NF_INTK)을 한번 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
> df_D909030301_intk %>% head(15)
ID N_MEAL N_DNAME N_FNAME NF_INTK
1 D909030301 3 캘리포니아롤 밀, 빵가루 0.0023360852
2 D909030301 3 캘리포니아롤 후추, 검은후추, 가루 0.0002625378
3 D909030301 3 캘리포니아롤 소금 0.0354167283
4 D909030301 3 캘리포니아롤 소금, 굵은소금 0.0001666599
5 D909030301 3 캘리포니아롤 조미료, 쇠고기맛, 가루 0.0005145871
6 D909030301 3 캘리포니아롤 겨자, 머스타드소스 0.0053733991
7 D909030301 3 캘리포니아롤 마요네즈, 전란 0.1611602944
8 D909030301 3 캘리포니아롤 돈까스 소스 0.0080704691
9 D909030301 3 캘리포니아롤 고추장, 개량 0.0043942804
10 D909030301 3 캘리포니아롤 고춧가루, 가루 0.0015594302
11 D909030301 3 캘리포니아롤 간장, 개량, 양조 0.0471246926
12 D909030301 3 캘리포니아롤 콩기름 0.0425762835
13 D909030301 3 캘리포니아롤 참기름 0.0861873348
14 D909030301 3 캘리포니아롤 올리브유 0.0004194558
15 D909030301 3 캘리포니아롤 옥수수기름 0.0094127088
|
cs |
역시 식품별로 보면 역시 후추나 소금 이런 건 미세한 양으로 섭취량이 되어 있습니다.
연구를 하시는 분들이 식품명 자체보다는 영양 관점에서 분석한다고 하면 식품이 아닌 식품군 분류(상위)로 필요할 것 같은데 이용자 지침서에 보면 역시 식품군 분류(N_KINDG1,2)라는 변수가 있습니다. 즉 이런 식품종류가 너무 많을 수 있으니 식품군 분류 값 기준으로 섭취량을 계산하는 게 연구하는데 훨씬 효율적이겠지요?
2018년도 데이터의 음식명과 식품명이 몇 개나 될지 한번 확인해볼까요?
음식명(N_DNAME)은 10,372개 식품명은(N_FNAME) 3,079개의 종류가 있네요.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
df_hn18_24rc %>% group_by(N_DNAME) %>% tally()
# A tibble: 10,372 x 2
N_DNAME n
<fct> <int>
1 ?지감자 3
2 ?파춥스 1
3 2%음료 1
4 2%음료,복숭아맛 1
5 2프로부족할때 1
6 3분미트볼 1
7 3분소고기간짜장 1
8 3분카레 2
9 ABC초콜렛 9
10 ABC초콜릿 1
# ... with 10,362 more rows
df_hn18_24rc %>% group_by(N_FNAME) %>% tally()
# A tibble: 3,079 x 2
N_FNAME n
<fct> <int>
1 가다랑어 육수 90
2 가다랑어, 반건 68
3 가다랑어, 유지통조림 348
4 가당음료,2%부족할때(롯데칠성음료) 2
5 가당음료,귀여운내친구뽀로로 딸기맛((주)팔도) 1
6 가당음료,귀여운내친구뽀로로 밀크맛(한국야쿠르트) 9
7 가당음료,썬키스트 레몬에이드(해태) 2
8 가당음료,파워오투 아이스베리((주)농심) 1
9 가당음료,파워오투 애플키위((주)농심) 3
10 가당음료,파워오투 오렌지레몬((주)농심) 3
# ... with 3,069 more rows
|
cs |
역시 분석을 효율적으로 하기 위해서는 식품군별로 보는 게 좋을 것 같은데 이용자 지침서에는 식품군이 2종류로 나옵니다. 분류방식이 식품군 분류 1(N_KINDG1)은 22가지로, 식품군 분류 2(N_KINDG2)는 18가지 종류로 나누어지네요
일단 해당 식품군별로 카운팅을 해보았습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
df_hn18_24rc %>% group_by(N_KINDG1) %>% tally()
# A tibble: 20 x 2
N_KINDG1 n
<int> <int>
1 1 50544
2 2 6459
3 3 24624
4 4 11303
5 5 20021
6 6 144233
7 7 7163
8 8 11465
9 9 8420
10 11 98239
11 12 44424
12 13 270
13 15 28326
14 16 7648
15 17 26718
16 18 6092
17 19 1024
18 20 47
19 21 10265
20 22 2534
df_hn18_24rc %>% group_by(N_KINDG2) %>% tally()
# A tibble: 18 x 2
N_KINDG2 n
<int> <int>
1 1 49379
2 2 6478
3 3 21609
4 4 11303
5 5 20021
6 6 144627
7 7 7163
8 8 14946
9 9 28114
10 10 7648
11 11 26715
12 12 8419
13 13 6146
14 14 45394
15 15 11905
16 16 97812
17 17 1472
18 18 668
|
cs |
마지막으로 데이터 건수가 가장 많은 이분이 하루 동안 가장 많이 먹은 음식을 한번 살펴보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL,N_KINDG1) %>%
summarise(sum(NF_INTK)) ->df_D909030301_sum
colnames(df_D909030301_sum) <- c(names(df_D909030301_sum)[1:3],"sum_intk")
df_D909030301_sum %>% arrange(desc(sum_intk))
# A tibble: 33 x 4
# Groups: ID, N_MEAL [4]
ID N_MEAL N_KINDG1 sum_intk
<fct> <int> <int> <dbl>
1 D909030301 3 21 501.
2 D909030301 3 18 324.
3 D909030301 2 1 275.
4 D909030301 1 1 186.
5 D909030301 4 21 168
6 D909030301 3 17 153.
7 D909030301 3 1 93.1
8 D909030301 3 8 81.7
9 D909030301 2 6 55.0
10 D909030301 1 7 44.9
# ... with 23 more rows
|
cs |
가장 많은 섭취량은 저녁(3) 식사시간에 501g을 섭취한 음료(21) 324g을 섭취한 우유류(18)이네요.
해산물 뷔페에 갔지만 생각보다 초밥류를 많이 먹지는 않은듯합니다. 3위가 점심(2) 때 먹은 곡류(1)이고 4위가 아침(1)에 먹은 곡류(1)입니다. 5위는 간식(4)에 포함된 또 음료(21)입니다. 6위에서 보면 153g으로 저녁(3)에 어패류(17) 항목이 보이네요. 이분은 생각보다 음료수 섭취량이 많으신 분이네요.
하지만 뷔페를 갔는데 끼니별 섭취량을 한번 다시 합산해보겠습니다.
역시 저녁(3)이 1223g으로 가장 양이 많네요. 이것이 바로 뷔페의 힘(?)이겠죠.(농담입니다)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
> #끼니별 섭취량
> df_hn18_24rc %>% filter(ID =="D909030301") %>% group_by(ID,N_MEAL) %>%
+ summarise(sum(NF_INTK)) -> df_D909030301_sum2
> colnames(df_D909030301_sum2) <- c(names(df_D909030301_sum2)[1:2],"sum_intk")
> df_D909030301_sum2 %>% arrange(desc(sum_intk))
# A tibble: 4 x 3
# Groups: ID [1]
ID N_MEAL sum_intk
<fct> <int> <dbl>
1 D909030301 3 1223.
2 D909030301 2 424.
3 D909030301 1 333.
4 D909030301 4 168
|
cs |
마무리
이상으로 국민건강 영양조사에서 식품섭취량 DB파일을 살펴보았습니다. 데이터셋이 어떤 식의 구조이고 어떻게 데이터를 담고 있는지는 변수와 여러 집계 함수를 이용해서 파악을 해보아야 합니다.
이전 포스팅에서는 기본 DB의 구조를 살짝 보긴 했는데 이번처럼 자세히 보지는 못했던 것 같네요.
이런 구조로 되어 있다는 걸 파악을 했으니 다음번에는 해당 데이터셋의 이상치(Outlier)를 찾는 방법을 함께 고민해보겠습니다.
함께보면 좋을 글
Introduction to DataExplorer
This document introduces the package DataExplorer, and shows how it can help you with different tasks throughout your data exploration process. The remaining of this guide will be organized in accordance with the goals. As the package evolves, more content
cran.r-project.org
R for Data Science
This book will teach you how to do data science with R: You’ll learn how to get your data into R, get it into the most useful structure, transform it, visualise it and model it. In this book, you will find a practicum of skills for data science. Just as
r4ds.had.co.nz
[DataMining] 2. 시각화를 통한 탐색적 데이터 분석(EDA)
데이터 시각화를 통한 탐색적 데이터 분석 탐색적 데이터 분석이란? 데이터에 대한 질문을 찾는다. 데이터에 대한 시각화, 변환, 모델링으로 답을 찾는다. 답을 통해 질문을 심화하고 새로운 질�
jtoday.tistory.com
'아재도 하는 데이터분석' 카테고리의 다른 글
| "[부산 아파트 가격 예측 1편] 2020-2024 부산 남구 실거래 데이터 분석 및 시각화" (0) | 2024.12.25 |
|---|---|
| [데이터소개] 스타벅스 매장은 지난 1년간 얼마나 늘었을까?(feat. 스타벅스 매장 목록 파일, 2023.06.15.) (1) | 2023.06.17 |
| [데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC) (0) | 2020.05.19 |
| [데이터분석] 한우 사육현황 데이터 시각화 feat by ggplot2 & Excel (2) | 2020.05.16 |
| [데이터분석] 일자리가 가장 많은 동네는?(feat by 국세통계 연말정산 신고현황) (0) | 2020.03.11 |