

들어가며
지난 1,2편을 통해서 부산 남구 아파트의 실거래가 데이터를 가지고 특징을 살펴보았습니다. 이제 실거래가 데이터를 가지고서 간단하게 '거래금액'을 예측하는 모델을 만들어서 확인해보겠습니다. 여러가지 머신러닝 기법들이 있는데 가장 직관적인 회귀모형(Linear Regression), 의사결정나무(Decison Tree)기반의 RandomForest, 의사결정나무 같은 학습법을 추가로 학습하는 Gradient Boosting 기반의 XgBoost, Gradient Boosting 을 더 개선한 LightGbm 모델, 그리고 Elastic Net, Ranger, SVR 등으로 예측모델을 만들어서 비교를 해보도록 하겠습니다.
학습용 데이터셋 정리
머신러닝 기법은 기본적으로 데이터셋이 학습에 적합하도록 적당한 변환이 필요합니다. 실거래가 데이터셋에서 가격에 영향을 줄수 있는 변수들만 최소한으로 추출합니다.
| "법정동시군구코드" "법정동읍면동코드" "법정동지번코드" "법정동본번코드" "법정동부번코드" "도로명" "도로명시군구코드" "도로명코드" "단지명" "지번" "전용면적" "계약년도" "계약월" "계약일" "거래금액" "층" "건축년도" "단지일련번호" "해제여부" "해제사유발생일" "아파트동명" "토지임대부아파트여부" "법정동코드" "시도명" "시군구명" "읍면동명" "계약일자" |
계약년도+계약월+계약일을 기준으로 생성한 "계약일자", 전용면적, 거층, 건축년도, 동명이 실거래가 데이터셋에서는 그나마 가격에 영향을 주는 변수로 생각하고 학습용 데이터셋을 만들었습니다.
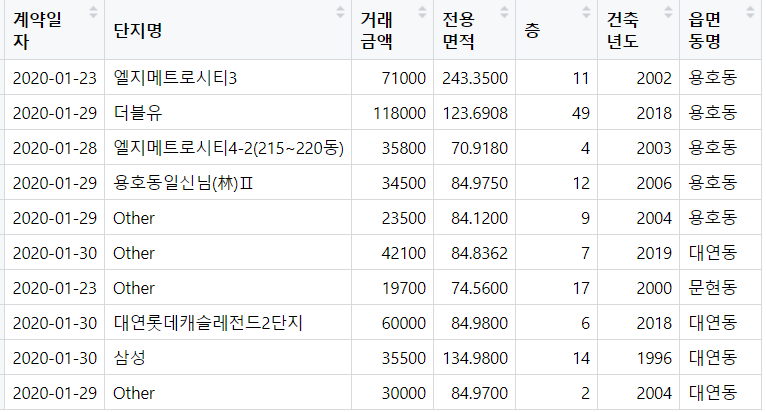
단지명과 동명의 경우 Char 타입인데, 학습을 위해서 범주형(Factor)변수로 변환을 해줍니다.

훈련및 검증용 데이터셋 분리
이후 현제 14,116개의 데이터를 학습용 데이터 80%, 테스트용 데이터 20%로 나눕니다.
| # 데이터 분할 (학습:테스트 = 8:2) set.seed(123) train_idx <- createDataPartition(df_model$거래금액, p = 0.8, list = FALSE) train_data <- df_model[train_idx, ] test_data <- df_model[-train_idx, ] |
머신러닝 모델 성능지표 생성
각각의 머신러닝 모델들의 성능을 확인할 지표로 RMSE, MAE, R2 값을 측정할 함수를 만들어서 만든 모델중 어떤 모델이 더 성능이 좋은지 비교해보겠습니다.
| # 평가 지표 계산 함수 calculate_metrics <- function(actual, predicted) { rmse <- sqrt(mean((actual - predicted)^2)) mae <- mean(abs(actual - predicted)) r2 <- cor(actual, predicted)^2 return(list(RMSE = rmse, MAE = mae, R2 = r2)) } |
머신러닝 모델 정의
1. Linear Regression
설명
선형 회귀(Linear Regression)는 머신러닝에서 가장 기본적인 알고리즘으로, 데이터를 이용해 직선의 방정식을 만들어 예측하는 방법입니다. 예를 들어, "공부 시간"과 "시험 점수"의 관계를 분석할 때, 공부 시간이 늘어나면 시험 점수가 어떻게 변할지를 직선으로 나타냅니다. 수학적으로는 y=wx+by = wx + b라는 방정식을 사용하며, yy는 결과값, xx는 입력값, ww는 기울기, bb는 절편입니다. 데이터를 통해 ww와 bb 값을 찾아 예측에 활용합니다.
장점은 단순하고 해석이 쉬우며, 계산이 빠르다는 점입니다. 하지만, 데이터가 직선으로 설명되지 않는 경우(비선형 데이터)나 변수 간 상관관계가 강한 경우에는 성능이 떨어질 수 있습니다. 주로 데이터를 분석하거나 간단한 문제를 해결할 때 유용합니다.
모델정의
| # 1. 선형회귀모델 (lm) lm_model <- function(train_data, test_data) { model <- lm(거래금액 ~ ., data = train_data) predictions <- predict(model, test_data) predictions_list[["LM"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
2. Random Forest
설명
Random Forest는 머신러닝에서 널리 사용되는 알고리즘으로, 여러 개의 의사결정나무(Decision Trees)를 조합하여 예측을 개선하는 방법입니다. 각 나무는 데이터를 무작위로 샘플링하고, 일부 특징만 사용해 학습합니다. 이를 통해 과적합(Overfitting)을 방지하고 더 일반화된 예측을 할 수 있습니다. 결과를 얻을 때, 회귀 문제에서는 각 나무의 평균값을 사용하고, 분류 문제에서는 다수결 투표로 최종 결과를 결정합니다. Random Forest는 비교적 정확도가 높고, 변수의 중요도를 확인할 수 있어 해석이 용이합니다. 다만, 대규모 데이터에서는 속도가 느릴 수 있습니다
모델정의
| # 2. Random Forest 모델 rf_model <- function(train_data, test_data) { model <- randomForest(거래금액 ~ ., data = train_data, ntree = 500) predictions <- predict(model, test_data) predictions_list[["RF"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
3. XGBoost
설명
XGBoost는 머신러닝에서 높은 성능을 자랑하는 알고리즘으로, 주로 대회나 실무에서 많이 사용됩니다. "Extreme Gradient Boosting"의 약자로, 여러 약한 학습자(보통 의사결정나무)를 순차적으로 학습시켜 예측력을 개선합니다. 각 단계에서 이전 모델이 놓친 부분을 집중적으로 학습하며, 이를 "Gradient Boosting"이라 부릅니다. XGBoost는 계산 속도가 빠르고, 과적합을 줄이기 위한 규제(Regularization) 기능이 있어 효율적입니다. 또한, 결측치 처리와 병렬 처리 등 다양한 최적화 기술이 적용되어 실용성이 높습니다. 데이터가 크거나 복잡한 문제에서도 강력한 성능을 발휘하지만, 초보자에게는 이해와 튜닝이 조금 어려울 수 있습니다.
모델정의
| # 3. XGBoost 모델 xgb_model <- function(train_data, test_data) { # 데이터 변환 train_matrix <- model.matrix(거래금액 ~ ., data = train_data)[,-1] test_matrix <- model.matrix(거래금액 ~ ., data = test_data)[,-1] dtrain <- xgb.DMatrix(train_matrix, label = train_data$거래금액) dtest <- xgb.DMatrix(test_matrix, label = test_data$거래금액) params <- list( objective = "reg:squarederror", eta = 0.1, max_depth = 6, nrounds = 100 ) model <- xgb.train(params, dtrain, nrounds = 100) predictions <- predict(model, dtest) predictions_list[["XGB"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
4. LightGBM
설명
LightGBM은 머신러닝에서 자주 사용되는 고성능 알고리즘으로, "Light Gradient Boosting Machine"의 약자입니다. Gradient Boosting 방식을 기반으로 하면서, 더 가볍고 빠른 속도를 목표로 만들어졌습니다. 데이터를 수직 방향(Leaf-wise)으로 분할하며, 효율적으로 학습하여 높은 성능을 발휘합니다. 대규모 데이터와 고차원 데이터를 처리하는 데 적합하며, 결측치와 범주형 데이터도 잘 다룹니다. LightGBM은 메모리 사용량이 적고 학습 시간이 빠르며, 정확도도 높은 편입니다. 다만, 작은 데이터셋에서는 과적합이 발생할 가능성이 있어 신중한 튜닝이 필요합니다. 초보자에게는 XGBoost보다 설정이 간단해 비교적 쉽게 시작할 수 있습니다.
모델정의
| # 4. LightGBM 모델 lgb_model <- function(train_data, test_data) { # 데이터 변환 train_matrix <- model.matrix(거래금액 ~ ., data = train_data)[,-1] test_matrix <- model.matrix(거래금액 ~ ., data = test_data)[,-1] dtrain <- lgb.Dataset(train_matrix, label = train_data$거래금액) params <- list( objective = "regression", metric = "rmse", learning_rate = 0.1, num_leaves = 31 ) model <- lgb.train(params, dtrain, nrounds = 100) predictions <- predict(model, test_matrix) predictions_list[["LGB"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
5. Elastic Net
설명
Elastic Net은 선형 회귀(Linear Regression)에서 모델의 복잡성을 조절하기 위해 사용하는 정규화 기법입니다. 간단히 말해, 모델이 너무 복잡해져서 과적합(Overfitting)이 발생하는 것을 막아줍니다. Elastic Net은 두 가지 정규화 방법, L1 정규화(Lasso)와 L2 정규화(Ridge)를 결합한 모델입니다.
L1 정규화는 중요한 변수만 선택하도록 유도하고, L2 정규화는 변수 간의 균형을 맞추는 역할을 합니다. Elastic Net은 이 두 가지를 조합하여 데이터의 특성에 따라 적절히 조정할 수 있습니다.
이 모델은 변수 선택이 필요한 고차원 데이터나 변수 간 상관관계가 높은 데이터에서 특히 유용합니다. 장점은 Lasso와 Ridge의 장점을 모두 활용할 수 있다는 점이지만, 적절한 하이퍼파라미터 조정이 필요합니다. 따라서 데이터를 효율적으로 다루는 데 유용하면서도 직관적인 방법을 제공합니다.
모델정의
| # 5. Elastic Net 모델 (LASSO와 Ridge의 장점을 결합) elastic_net_model <- function(train_data, test_data) { # 데이터 준비 x_train <- model.matrix(거래금액 ~ . - 1, data = train_data) y_train <- train_data$거래금액 x_test <- model.matrix(거래금액 ~ . - 1, data = test_data) # 교차 검증으로 최적 파라미터 찾기 cv_fit <- cv.glmnet(x_train, y_train, alpha = 0.5) # 예측 predictions <- predict(cv_fit, x_test, s = "lambda.min") return(calculate_metrics(test_data$거래금액, predictions)) } |
6. Support Vector Regression(SVR)
설명
Support Vector Regression(SVR)은 회귀 문제를 해결하는 머신러닝 알고리즘으로, 데이터에 가장 잘 맞는 "최적의 결정 경계"를 찾는 Support Vector Machine(SVM)의 아이디어를 활용합니다.
SVR은 주어진 데이터에서 특정 허용 오차(ε) 이내에 들어오는 예측값을 허용하며, 이 범위를 벗어나는 데이터에 대해 패널티를 부여해 모델을 학습시킵니다. 즉, 데이터가 허용 범위 안에 있다면 모델은 이를 완벽히 맞추려고 하지 않아도 됩니다.
이 모델은 선형뿐만 아니라, 커널 함수(예: RBF, 다항식)를 사용해 비선형 관계도 잘 다룰 수 있습니다. SVR의 장점은 높은 예측 정확도와 복잡한 데이터 패턴을 처리할 수 있다는 점입니다. 하지만, 데이터가 많거나 고차원일 경우 학습 시간이 오래 걸릴 수 있습니다. 적은 데이터에서 높은 성능을 낼 수 있어 소규모 회귀 문제에 적합합니다.
모델정의
| # 6. SVR (Support Vector Regression) with RBF kernel svr_model <- function(train_data, test_data) { # 데이터 스케일링 preProc <- preProcess(train_data[, -which(names(train_data) == "거래금액")], method = c("center", "scale")) train_scaled <- predict(preProc, train_data) test_scaled <- predict(preProc, test_data) # 모델 학습 model <- ksvm(거래금액 ~ ., data = train_scaled, kernel = "rbfdot", C = 10, epsilon = 0.1) # 예측 predictions <- predict(model, test_scaled) predictions_list[["SVR"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
7. Ranger
설명
Ranger는 Random Forest 알고리즘의 확장 버전으로, 대규모 데이터와 고차원 데이터를 빠르게 처리할 수 있도록 최적화된 머신러닝 모델입니다.
기본적으로 Random Forest처럼 여러 개의 의사결정나무를 생성해 예측을 수행하지만, 속도를 높이고 메모리 사용량을 줄이기 위해 효율적으로 구현되었습니다. 특히, 고차원 데이터와 희소 데이터(sparse data)를 처리하는 데 강점이 있습니다.
Ranger는 회귀와 분류 문제뿐만 아니라 생존 분석(survival analysis) 등 다양한 문제에도 활용할 수 있습니다. 기본 Random Forest와 유사하게 과적합(Overfitting)에 강하고, 변수 중요도(Variable Importance)를 확인할 수 있는 장점이 있습니다.
데이터가 크거나 계산 속도가 중요한 경우 사용하기 적합하며, R과 Python에서 쉽게 사용할 수 있습니다. Ranger는 머신러닝 초보자에게도 Random Forest처럼 친숙한 옵션으로 추천됩니다.
모델정의
| # 7. Ranger (더 빠르고 효율적인 Random Forest 구현) ranger_model <- function(train_data, test_data) { model <- ranger(거래금액 ~ ., data = train_data, num.trees = 500, importance = 'impurity') predictions <- predict(model, test_data)$predictions predictions_list[["Ranger"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
모델별 성능 지표 확인
성능지표로 RMSE, MAE, R2를 사용하고 각 모델별 수행시간을 측정하여 최종적으로 효율성 지표까지 만들어서 확인해보겠습니다. 효율성 지표(Efficiency)는 RMSE/Execution Time으로 만든 값입니다.
1. RMSE (Root Mean Squared Error)
|
2. MAE (Mean Absolute Error)
|
3. R² (R-squared, 결정 계수)
|
요약
|
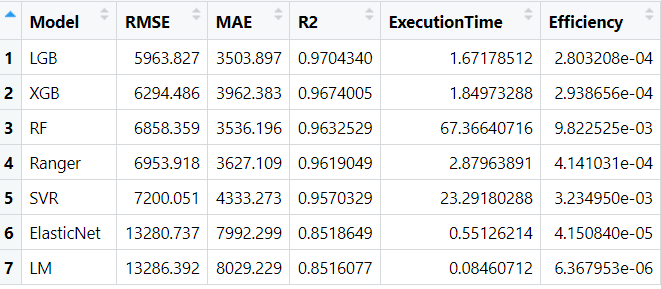
이렇게 각 지표를 기준으로 테스트셋으로 수행한 지표는 아래와 같습니다. RMSE값이 가장 적은(잘 맞춘) 순으로 정렬되었습니다. LGB(LightGBM)모델이 RMSE값이 가장 낮습니다. RMSE의 값은 직관적으로 이해 하자면, 예측된 값과 실제값의 차이가 5963만원 정도 난다는 것으로 받아들이면 좋을것 같습니다. XGB(XgBoost)모델이 2위이구요. LM(회귀모형)이 가장 값이 높아서 예측력이 떨어지는 편이라고 이해하면 될것같습니다.
MAE 지표 역시 비슷한 개념이지만 오차값에 대한 절대값이라 오차가 큰 경우 설명력이 약해질수 있습니다.
MAE기준으로 보면 LGB, RF, Ranger, XGB 순으로 RandomForest가 XgBoost보다 괜찮게 나오네요.
여기서 수행시간(제 노트북에서 실행한 시간)기준으로 보면 RF가 가장 오래걸리고, SVR도 역시 오래걸리네요. 성능이 좋은 LGB, XGB가 2초가 안걸리는 훌룡한 속도를 보여줬습니다.
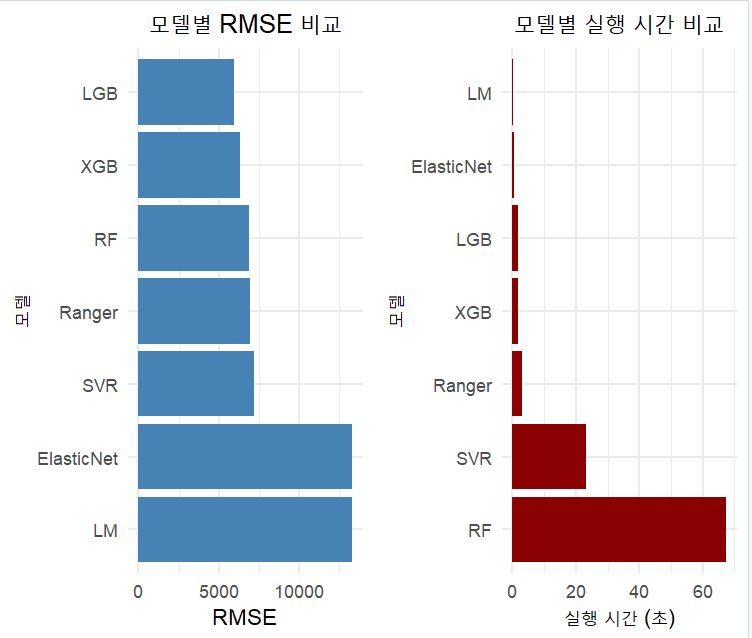
표로 보면 어려우니 시각화를 해서 비교해보겠습니다. 한눈에 평가지표와 성능이 보이시죠?
역시 LGB가 상당히 좋아 보입니다.
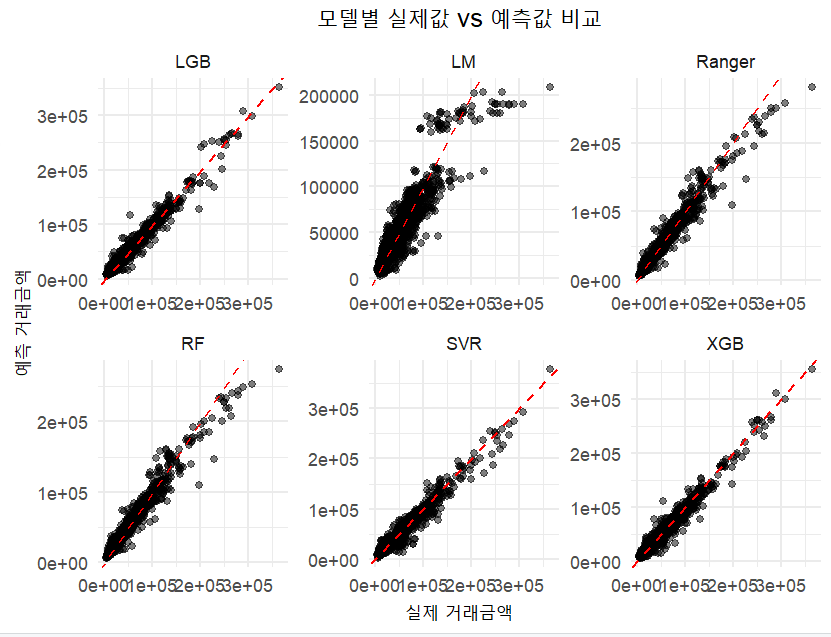
각 모델별로 테스트 데이터를 어느정도 맞췄는지 산점도를 그려서 살펴보겠습니다. 산점도는 x축에 실제거래금액을 y축에 모델이 에측한 거래금액을 기준으로 산점도를 그린것입니다. 이 산점도가 기울기가 1인 선에 근접할수록 정확히 맞춘것으로 보이겠지요? LGB, XGB모델이 기울기1인 직선에 근접하게 점들이 모여 있는게 보이시죠?
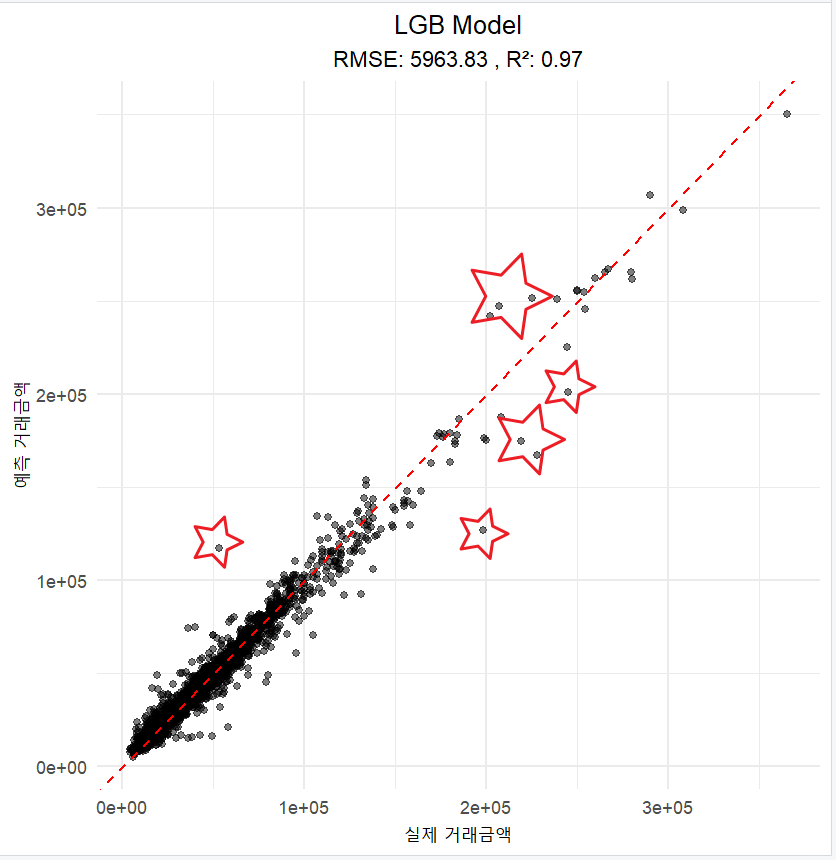
가장 RMSE값이 작은 LGB모델만 살펴보면 이런 모습입니다. 점선 기준으로 많이 벗어난 데이터들이 왜 예측값의 차이가 많은지 실제값보다 더 높게 예측된 것들과 낮게 예측된 것들을 살펴보면, 뭔가 더 보완할 변수가 생각이 날까요?
마무리
이번 포스팅은 실거래가 데이터셋에 거래금액에 영향을 미칠수 있는 변수들만을 가지고 단순한 예측모델을 만들어서 각 모델별로 성능을 비교해보았습니다. 아직은 RMSE기준으로 5~6천만원의 차이가 있는 상태의 모델입니다. 아파트 가격에 영향을 미치는 다른 많은 변수들(예를 들어 아파트 세대수, 학군, 초품아, 상권, 주차대수, 평지 여부)을 데이터셋에 결합한다면 뭔가 더 성능이 좋은 모델을 만들수 있지 않을까요?
다음 포스팅을 기대해주세요.
함께 보면 좋을
* 데이콘의 2016년 아파트 실거래가 예측 경진대
https://dacon.io/competitions/official/21265/overview/description
아파트 실거래가 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
* 데이콘의 아파트 실거래가 예측 프로젝
아파트 실거래가 예측 프로젝트 🏬
아파트 실거래가 예측 프로젝트 통해 머신러닝 대회에 참여하기 위한 기법을 배우세요. 창의력과 인내력으로 데이터 분석 실력을 향상시키세요.
dacon.io
* 빅재미 : 부동산데이터분석 : 아파트 집값 예측
https://blog.naver.com/cslee_official/223455799971
부동산 데이터 분석 : 아파트 집값 예측
안녕하세요!! 빅재미입니다.😁 최근 부동산 가격이 떨어지고 있다고는 하지만, 여전히 비싸고... 내 집 ...
blog.naver.com
* 정보처리학회 논문(2023) : 딥러닝과 머신러닝을 이용한 실거래가 예측
딥러닝과 머신러닝을 이용한 아파트 실거래가 예측
코로나 시대 이후 아파트 가격 상승은 비상식적이었다. 이러한 불확실한 부동산 시장에서 가격 예측 연구는 매우 중요하다. 본 논문에서는다양한 부동산 사이트에서 자료 수집 및 크롤링을 통
www.kci.go.kr
* 기계학습을 이용한 아파트 매매가격 예측 연구
* 공간적 상관성을 고려한 딥러닝 기반 부동산 가격 예측 방법 제안
https://ki-it.com/xml/39412/39412.pdf
'아재도 하는 데이터분석' 카테고리의 다른 글
| [부산 아파트 가격 예측 2편] 부산 남구 아파트 실거래가 데이터 분석: 거래량, 금액, 주요 단지 트렌드 (0) | 2024.12.28 |
|---|---|
| "[부산 아파트 가격 예측 1편] 2020-2024 부산 남구 실거래 데이터 분석 및 시각화" (0) | 2024.12.25 |
| [데이터소개] 스타벅스 매장은 지난 1년간 얼마나 늘었을까?(feat. 스타벅스 매장 목록 파일, 2023.06.15.) (1) | 2023.06.17 |
| [데이터 소개] 국민건강영양조사 2편(Feat. R DataExplorer) (1) | 2020.05.21 |
| [데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC) (0) | 2020.05.19 |
들어가며
지난 1,2편을 통해서 부산 남구 아파트의 실거래가 데이터를 가지고 특징을 살펴보았습니다. 이제 실거래가 데이터를 가지고서 간단하게 '거래금액'을 예측하는 모델을 만들어서 확인해보겠습니다. 여러가지 머신러닝 기법들이 있는데 가장 직관적인 회귀모형(Linear Regression), 의사결정나무(Decison Tree)기반의 RandomForest, 의사결정나무 같은 학습법을 추가로 학습하는 Gradient Boosting 기반의 XgBoost, Gradient Boosting 을 더 개선한 LightGbm 모델, 그리고 Elastic Net, Ranger, SVR 등으로 예측모델을 만들어서 비교를 해보도록 하겠습니다.
학습용 데이터셋 정리
머신러닝 기법은 기본적으로 데이터셋이 학습에 적합하도록 적당한 변환이 필요합니다. 실거래가 데이터셋에서 가격에 영향을 줄수 있는 변수들만 최소한으로 추출합니다.
| "법정동시군구코드" "법정동읍면동코드" "법정동지번코드" "법정동본번코드" "법정동부번코드" "도로명" "도로명시군구코드" "도로명코드" "단지명" "지번" "전용면적" "계약년도" "계약월" "계약일" "거래금액" "층" "건축년도" "단지일련번호" "해제여부" "해제사유발생일" "아파트동명" "토지임대부아파트여부" "법정동코드" "시도명" "시군구명" "읍면동명" "계약일자" |
계약년도+계약월+계약일을 기준으로 생성한 "계약일자", 전용면적, 거층, 건축년도, 동명이 실거래가 데이터셋에서는 그나마 가격에 영향을 주는 변수로 생각하고 학습용 데이터셋을 만들었습니다.
단지명과 동명의 경우 Char 타입인데, 학습을 위해서 범주형(Factor)변수로 변환을 해줍니다.
훈련및 검증용 데이터셋 분리
이후 현제 14,116개의 데이터를 학습용 데이터 80%, 테스트용 데이터 20%로 나눕니다.
| # 데이터 분할 (학습:테스트 = 8:2) set.seed(123) train_idx <- createDataPartition(df_model$거래금액, p = 0.8, list = FALSE) train_data <- df_model[train_idx, ] test_data <- df_model[-train_idx, ] |
머신러닝 모델 성능지표 생성
각각의 머신러닝 모델들의 성능을 확인할 지표로 RMSE, MAE, R2 값을 측정할 함수를 만들어서 만든 모델중 어떤 모델이 더 성능이 좋은지 비교해보겠습니다.
| # 평가 지표 계산 함수 calculate_metrics <- function(actual, predicted) { rmse <- sqrt(mean((actual - predicted)^2)) mae <- mean(abs(actual - predicted)) r2 <- cor(actual, predicted)^2 return(list(RMSE = rmse, MAE = mae, R2 = r2)) } |
머신러닝 모델 정의
1. Linear Regression
설명
선형 회귀(Linear Regression)는 머신러닝에서 가장 기본적인 알고리즘으로, 데이터를 이용해 직선의 방정식을 만들어 예측하는 방법입니다. 예를 들어, "공부 시간"과 "시험 점수"의 관계를 분석할 때, 공부 시간이 늘어나면 시험 점수가 어떻게 변할지를 직선으로 나타냅니다. 수학적으로는 y=wx+by = wx + b라는 방정식을 사용하며, yy는 결과값, xx는 입력값, ww는 기울기, bb는 절편입니다. 데이터를 통해 ww와 bb 값을 찾아 예측에 활용합니다.
장점은 단순하고 해석이 쉬우며, 계산이 빠르다는 점입니다. 하지만, 데이터가 직선으로 설명되지 않는 경우(비선형 데이터)나 변수 간 상관관계가 강한 경우에는 성능이 떨어질 수 있습니다. 주로 데이터를 분석하거나 간단한 문제를 해결할 때 유용합니다.
모델정의
| # 1. 선형회귀모델 (lm) lm_model <- function(train_data, test_data) { model <- lm(거래금액 ~ ., data = train_data) predictions <- predict(model, test_data) predictions_list[["LM"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
2. Random Forest
설명
Random Forest는 머신러닝에서 널리 사용되는 알고리즘으로, 여러 개의 의사결정나무(Decision Trees)를 조합하여 예측을 개선하는 방법입니다. 각 나무는 데이터를 무작위로 샘플링하고, 일부 특징만 사용해 학습합니다. 이를 통해 과적합(Overfitting)을 방지하고 더 일반화된 예측을 할 수 있습니다. 결과를 얻을 때, 회귀 문제에서는 각 나무의 평균값을 사용하고, 분류 문제에서는 다수결 투표로 최종 결과를 결정합니다. Random Forest는 비교적 정확도가 높고, 변수의 중요도를 확인할 수 있어 해석이 용이합니다. 다만, 대규모 데이터에서는 속도가 느릴 수 있습니다
모델정의
| # 2. Random Forest 모델 rf_model <- function(train_data, test_data) { model <- randomForest(거래금액 ~ ., data = train_data, ntree = 500) predictions <- predict(model, test_data) predictions_list[["RF"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
3. XGBoost
설명
XGBoost는 머신러닝에서 높은 성능을 자랑하는 알고리즘으로, 주로 대회나 실무에서 많이 사용됩니다. "Extreme Gradient Boosting"의 약자로, 여러 약한 학습자(보통 의사결정나무)를 순차적으로 학습시켜 예측력을 개선합니다. 각 단계에서 이전 모델이 놓친 부분을 집중적으로 학습하며, 이를 "Gradient Boosting"이라 부릅니다. XGBoost는 계산 속도가 빠르고, 과적합을 줄이기 위한 규제(Regularization) 기능이 있어 효율적입니다. 또한, 결측치 처리와 병렬 처리 등 다양한 최적화 기술이 적용되어 실용성이 높습니다. 데이터가 크거나 복잡한 문제에서도 강력한 성능을 발휘하지만, 초보자에게는 이해와 튜닝이 조금 어려울 수 있습니다.
모델정의
| # 3. XGBoost 모델 xgb_model <- function(train_data, test_data) { # 데이터 변환 train_matrix <- model.matrix(거래금액 ~ ., data = train_data)[,-1] test_matrix <- model.matrix(거래금액 ~ ., data = test_data)[,-1] dtrain <- xgb.DMatrix(train_matrix, label = train_data$거래금액) dtest <- xgb.DMatrix(test_matrix, label = test_data$거래금액) params <- list( objective = "reg:squarederror", eta = 0.1, max_depth = 6, nrounds = 100 ) model <- xgb.train(params, dtrain, nrounds = 100) predictions <- predict(model, dtest) predictions_list[["XGB"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
4. LightGBM
설명
LightGBM은 머신러닝에서 자주 사용되는 고성능 알고리즘으로, "Light Gradient Boosting Machine"의 약자입니다. Gradient Boosting 방식을 기반으로 하면서, 더 가볍고 빠른 속도를 목표로 만들어졌습니다. 데이터를 수직 방향(Leaf-wise)으로 분할하며, 효율적으로 학습하여 높은 성능을 발휘합니다. 대규모 데이터와 고차원 데이터를 처리하는 데 적합하며, 결측치와 범주형 데이터도 잘 다룹니다. LightGBM은 메모리 사용량이 적고 학습 시간이 빠르며, 정확도도 높은 편입니다. 다만, 작은 데이터셋에서는 과적합이 발생할 가능성이 있어 신중한 튜닝이 필요합니다. 초보자에게는 XGBoost보다 설정이 간단해 비교적 쉽게 시작할 수 있습니다.
모델정의
| # 4. LightGBM 모델 lgb_model <- function(train_data, test_data) { # 데이터 변환 train_matrix <- model.matrix(거래금액 ~ ., data = train_data)[,-1] test_matrix <- model.matrix(거래금액 ~ ., data = test_data)[,-1] dtrain <- lgb.Dataset(train_matrix, label = train_data$거래금액) params <- list( objective = "regression", metric = "rmse", learning_rate = 0.1, num_leaves = 31 ) model <- lgb.train(params, dtrain, nrounds = 100) predictions <- predict(model, test_matrix) predictions_list[["LGB"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
5. Elastic Net
설명
Elastic Net은 선형 회귀(Linear Regression)에서 모델의 복잡성을 조절하기 위해 사용하는 정규화 기법입니다. 간단히 말해, 모델이 너무 복잡해져서 과적합(Overfitting)이 발생하는 것을 막아줍니다. Elastic Net은 두 가지 정규화 방법, L1 정규화(Lasso)와 L2 정규화(Ridge)를 결합한 모델입니다.
L1 정규화는 중요한 변수만 선택하도록 유도하고, L2 정규화는 변수 간의 균형을 맞추는 역할을 합니다. Elastic Net은 이 두 가지를 조합하여 데이터의 특성에 따라 적절히 조정할 수 있습니다.
이 모델은 변수 선택이 필요한 고차원 데이터나 변수 간 상관관계가 높은 데이터에서 특히 유용합니다. 장점은 Lasso와 Ridge의 장점을 모두 활용할 수 있다는 점이지만, 적절한 하이퍼파라미터 조정이 필요합니다. 따라서 데이터를 효율적으로 다루는 데 유용하면서도 직관적인 방법을 제공합니다.
모델정의
| # 5. Elastic Net 모델 (LASSO와 Ridge의 장점을 결합) elastic_net_model <- function(train_data, test_data) { # 데이터 준비 x_train <- model.matrix(거래금액 ~ . - 1, data = train_data) y_train <- train_data$거래금액 x_test <- model.matrix(거래금액 ~ . - 1, data = test_data) # 교차 검증으로 최적 파라미터 찾기 cv_fit <- cv.glmnet(x_train, y_train, alpha = 0.5) # 예측 predictions <- predict(cv_fit, x_test, s = "lambda.min") return(calculate_metrics(test_data$거래금액, predictions)) } |
6. Support Vector Regression(SVR)
설명
Support Vector Regression(SVR)은 회귀 문제를 해결하는 머신러닝 알고리즘으로, 데이터에 가장 잘 맞는 "최적의 결정 경계"를 찾는 Support Vector Machine(SVM)의 아이디어를 활용합니다.
SVR은 주어진 데이터에서 특정 허용 오차(ε) 이내에 들어오는 예측값을 허용하며, 이 범위를 벗어나는 데이터에 대해 패널티를 부여해 모델을 학습시킵니다. 즉, 데이터가 허용 범위 안에 있다면 모델은 이를 완벽히 맞추려고 하지 않아도 됩니다.
이 모델은 선형뿐만 아니라, 커널 함수(예: RBF, 다항식)를 사용해 비선형 관계도 잘 다룰 수 있습니다. SVR의 장점은 높은 예측 정확도와 복잡한 데이터 패턴을 처리할 수 있다는 점입니다. 하지만, 데이터가 많거나 고차원일 경우 학습 시간이 오래 걸릴 수 있습니다. 적은 데이터에서 높은 성능을 낼 수 있어 소규모 회귀 문제에 적합합니다.
모델정의
| # 6. SVR (Support Vector Regression) with RBF kernel svr_model <- function(train_data, test_data) { # 데이터 스케일링 preProc <- preProcess(train_data[, -which(names(train_data) == "거래금액")], method = c("center", "scale")) train_scaled <- predict(preProc, train_data) test_scaled <- predict(preProc, test_data) # 모델 학습 model <- ksvm(거래금액 ~ ., data = train_scaled, kernel = "rbfdot", C = 10, epsilon = 0.1) # 예측 predictions <- predict(model, test_scaled) predictions_list[["SVR"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
7. Ranger
설명
Ranger는 Random Forest 알고리즘의 확장 버전으로, 대규모 데이터와 고차원 데이터를 빠르게 처리할 수 있도록 최적화된 머신러닝 모델입니다.
기본적으로 Random Forest처럼 여러 개의 의사결정나무를 생성해 예측을 수행하지만, 속도를 높이고 메모리 사용량을 줄이기 위해 효율적으로 구현되었습니다. 특히, 고차원 데이터와 희소 데이터(sparse data)를 처리하는 데 강점이 있습니다.
Ranger는 회귀와 분류 문제뿐만 아니라 생존 분석(survival analysis) 등 다양한 문제에도 활용할 수 있습니다. 기본 Random Forest와 유사하게 과적합(Overfitting)에 강하고, 변수 중요도(Variable Importance)를 확인할 수 있는 장점이 있습니다.
데이터가 크거나 계산 속도가 중요한 경우 사용하기 적합하며, R과 Python에서 쉽게 사용할 수 있습니다. Ranger는 머신러닝 초보자에게도 Random Forest처럼 친숙한 옵션으로 추천됩니다.
모델정의
| # 7. Ranger (더 빠르고 효율적인 Random Forest 구현) ranger_model <- function(train_data, test_data) { model <- ranger(거래금액 ~ ., data = train_data, num.trees = 500, importance = 'impurity') predictions <- predict(model, test_data)$predictions predictions_list[["Ranger"]] <<- predictions return(calculate_metrics(test_data$거래금액, predictions)) } |
모델별 성능 지표 확인
성능지표로 RMSE, MAE, R2를 사용하고 각 모델별 수행시간을 측정하여 최종적으로 효율성 지표까지 만들어서 확인해보겠습니다. 효율성 지표(Efficiency)는 RMSE/Execution Time으로 만든 값입니다.
1. RMSE (Root Mean Squared Error)
|
2. MAE (Mean Absolute Error)
|
3. R² (R-squared, 결정 계수)
|
요약
|
이렇게 각 지표를 기준으로 테스트셋으로 수행한 지표는 아래와 같습니다. RMSE값이 가장 적은(잘 맞춘) 순으로 정렬되었습니다. LGB(LightGBM)모델이 RMSE값이 가장 낮습니다. RMSE의 값은 직관적으로 이해 하자면, 예측된 값과 실제값의 차이가 5963만원 정도 난다는 것으로 받아들이면 좋을것 같습니다. XGB(XgBoost)모델이 2위이구요. LM(회귀모형)이 가장 값이 높아서 예측력이 떨어지는 편이라고 이해하면 될것같습니다.
MAE 지표 역시 비슷한 개념이지만 오차값에 대한 절대값이라 오차가 큰 경우 설명력이 약해질수 있습니다.
MAE기준으로 보면 LGB, RF, Ranger, XGB 순으로 RandomForest가 XgBoost보다 괜찮게 나오네요.
여기서 수행시간(제 노트북에서 실행한 시간)기준으로 보면 RF가 가장 오래걸리고, SVR도 역시 오래걸리네요. 성능이 좋은 LGB, XGB가 2초가 안걸리는 훌룡한 속도를 보여줬습니다.
표로 보면 어려우니 시각화를 해서 비교해보겠습니다. 한눈에 평가지표와 성능이 보이시죠?
역시 LGB가 상당히 좋아 보입니다.
각 모델별로 테스트 데이터를 어느정도 맞췄는지 산점도를 그려서 살펴보겠습니다. 산점도는 x축에 실제거래금액을 y축에 모델이 에측한 거래금액을 기준으로 산점도를 그린것입니다. 이 산점도가 기울기가 1인 선에 근접할수록 정확히 맞춘것으로 보이겠지요? LGB, XGB모델이 기울기1인 직선에 근접하게 점들이 모여 있는게 보이시죠?
가장 RMSE값이 작은 LGB모델만 살펴보면 이런 모습입니다. 점선 기준으로 많이 벗어난 데이터들이 왜 예측값의 차이가 많은지 실제값보다 더 높게 예측된 것들과 낮게 예측된 것들을 살펴보면, 뭔가 더 보완할 변수가 생각이 날까요?
마무리
이번 포스팅은 실거래가 데이터셋에 거래금액에 영향을 미칠수 있는 변수들만을 가지고 단순한 예측모델을 만들어서 각 모델별로 성능을 비교해보았습니다. 아직은 RMSE기준으로 5~6천만원의 차이가 있는 상태의 모델입니다. 아파트 가격에 영향을 미치는 다른 많은 변수들(예를 들어 아파트 세대수, 학군, 초품아, 상권, 주차대수, 평지 여부)을 데이터셋에 결합한다면 뭔가 더 성능이 좋은 모델을 만들수 있지 않을까요?
다음 포스팅을 기대해주세요.
함께 보면 좋을
* 데이콘의 2016년 아파트 실거래가 예측 경진대
https://dacon.io/competitions/official/21265/overview/description
아파트 실거래가 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
* 데이콘의 아파트 실거래가 예측 프로젝
아파트 실거래가 예측 프로젝트 🏬
아파트 실거래가 예측 프로젝트 통해 머신러닝 대회에 참여하기 위한 기법을 배우세요. 창의력과 인내력으로 데이터 분석 실력을 향상시키세요.
dacon.io
* 빅재미 : 부동산데이터분석 : 아파트 집값 예측
https://blog.naver.com/cslee_official/223455799971
부동산 데이터 분석 : 아파트 집값 예측
안녕하세요!! 빅재미입니다.😁 최근 부동산 가격이 떨어지고 있다고는 하지만, 여전히 비싸고... 내 집 ...
blog.naver.com
* 정보처리학회 논문(2023) : 딥러닝과 머신러닝을 이용한 실거래가 예측
딥러닝과 머신러닝을 이용한 아파트 실거래가 예측
코로나 시대 이후 아파트 가격 상승은 비상식적이었다. 이러한 불확실한 부동산 시장에서 가격 예측 연구는 매우 중요하다. 본 논문에서는다양한 부동산 사이트에서 자료 수집 및 크롤링을 통
www.kci.go.kr
* 기계학습을 이용한 아파트 매매가격 예측 연구
* 공간적 상관성을 고려한 딥러닝 기반 부동산 가격 예측 방법 제안
https://ki-it.com/xml/39412/39412.pdf
'아재도 하는 데이터분석' 카테고리의 다른 글
| [부산 아파트 가격 예측 2편] 부산 남구 아파트 실거래가 데이터 분석: 거래량, 금액, 주요 단지 트렌드 (0) | 2024.12.28 |
|---|---|
| "[부산 아파트 가격 예측 1편] 2020-2024 부산 남구 실거래 데이터 분석 및 시각화" (0) | 2024.12.25 |
| [데이터소개] 스타벅스 매장은 지난 1년간 얼마나 늘었을까?(feat. 스타벅스 매장 목록 파일, 2023.06.15.) (1) | 2023.06.17 |
| [데이터 소개] 국민건강영양조사 2편(Feat. R DataExplorer) (1) | 2020.05.21 |
| [데이터 소개] 국민건강영양조사 1편(Feat. 질병관리본부 KCDC) (0) | 2020.05.19 |