들어가며 위화~ 내가 참 좋아하는 중국 작가이다. 마치 군부독재 시절의 조정래 작가와 같은 느낌이 든다. 중국 문인이지만, 중국에서 환영받지 못하는~ 작가. 위화의 책들은 아마도 중국에서 발행이 되기는 할까? 홍콩정도에서만 가능하지 않을까? 하는 생각을 해보게 된다. (혹시 아시는 분?) 한번도 가보지 못한 중국이란 나라에 대해서 이렇게 소설을 통해서 조금씩 알아갈 뿐이다. 정말 대단한 중국이다. 독후감 중국의 근현대사에서 문화 대혁명 시기를 빼놓을 수 없듯이 위화의 이 소설에서도 어린 시절의 문화 대혁명 시절이 1권에 고스란히 녹아 있습니다. 계급 혁명, 계급투쟁을 외치던 혼란의 시대. 첫 시작이 화장실 엉덩이 사건으로 희화적이라면, 다시 어린시절의 이광두. 이광두의 엄마 이란, 재혼한 남편 송범평 그..
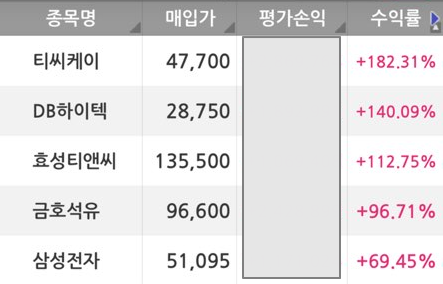
들어가며 제가 아주 오래전(2009년이라 아주 오래는 아닌가요?)부터 셀프펀드 방식의 투자를 해왔습니다. 오늘은 이 카테고리에 아주 오랫만의 포스팅인데요. 셀프펀드는 마법공식을 기반으로 해서 하는 투자법인데(해당 방식에 대해 궁금하신 분들은 마지막에 함께 보면 좋은 부분의 링크를 참고하시면 됩니다) 동일한 기준으로 기업을 선택하더라도 어떤 기업은 꽤 괜찮은 수익률을 , 어떤 기업은 시장보다 한참 안 좋은 수익률을 보여주기도 합니다. 같은 기준으로 선택한 기업인데, 시장 상황에 따라, 혹은 매수시기에 따라 편차가 나름 생기더라고요. 제 고민은 이런 편차를 없애고, 어떻게 하면 좋지 않은 수익률을 기록하는 기업을 투자대상에서 제외할 수 있을지를 찾는 데 있습니다만, 공부를 하면 할수록 쉽지 않아 보입니다. ..
어디서 살 것인가 : 우리가 살고 싶은 곳의 기준을 바꾸다 Author : 유현준 지음 Publisher : 을유문화사 Format : 380 pages ISBN : 9788932473802 도시에 대해 관심이 많은 나에게 끌린 책. 모종린 교수님의 '라이프스타일 도시'나 '골목길 자본론' 이런 책보다는 조금은 더 건축학적 관점에서 도시를 바라보는 시선이 있다. 우리의 도시를 이루고 있는 건축물들, 그 건축물이 인간과 사회에 미치는 영향들... 그래서 책 제목에서 말하는 "어디서 살것인가?" 라는 질문을 하게 만드는... 지금은 도시 한가운데 아파트에 살고 있는 나이지만, 어렸을 때 자라왔던 한국의 전형적인 시골집, 혹은 한옥집 같은 곳에 살아보고 싶기도 하다. 다만 나처럼 똥 손에 게으름과 귀차니즘이 ..
오늘도 울지 않고 살아낸 너에게 Author : 장재열 Translator : Publisher : 슬로래빗 Format : 240 pages, eBook ISBN : 9791186494172 알라딘 캐쉬로 첫 구매한 e북입니다. "오늘도 울지 않고 살아낸 너에게" 요즘 이런류의 에세이가 참 많죠. 책 표지에 있는것처럼 '어설픈 위로 대신 위안의 한마디를~' 요즘의 젊은 세대들의 힘든 상황때문에 그럴까요? 서점가에도 이런류의 책이 꽤 많더라구요.(이책은 나온지는 좀 된책이긴해요) 이 책의 저자 장재열은 삼성이라는 대기업에 들어갔다가 현재는 NGO에서 활동하고 있다네요. 삼수를 해서 명문대에 간 미대오빠인데, 삼성에서는 인사담당자로서 누군가를 합격명단의 엑셀 목록에서 삭제하는 자신의 역할에 회의를 느꼈다고..
나이가 들었나 보다. 예전의 노래들이 다시 들었을 때 또 다른 느낌이다. 최백호 님이 작년 8월 EBS space 공감 프로그램에서 부른 버전이다. 최백호 님의 연륜에서 목소리 톤까지, EBS 스튜디오에서 직관했더라면, 백퍼 눈물 흘렸을 것 같다. "사랑 그 쓸쓸함에 대하여"는 양희은 원곡이다. 가사를 한번 살펴 보자 다시 또 누군가를 만나서 사랑을 하게 될 수 있을까? 그럴 수는 없을 것 같아 도무지 알 수 없는 한 가지 사람을 사랑하게 되는 일 참 쓸쓸한 일인 것 같아 사랑이 끝나고 난 뒤에는 이세상도 끝나고 날 위해 빛나던 모든 것도 그 빛을 잃어버려 누구나 사는 동안에 한번 잊지 못할 사람을 만나고 잊지 못할 이별도 하지 도무지 알 수 없는 한 가지 사람을 사랑한다는 그일 참 쓸쓸한 일인 것 같아..
6월 이후 독태기(이북 카페에서 독서 권태기를 이렇게 줄여 부르더라)가 왔다. 올 초만 해도 꽤 맹렬한 기세였는데, 학교를 다니면 전공 관련된 책들을 접하다 보니 책을 읽고 싶은 마음들이, 읽고 싶은 책들이 생기지 않았다. 학교 도서관에 가서 전공 관련된 책들을 빌리다가 이번에 다시 읽고 싶었던 임경선 작가의 최근 에세이를 찾게 되었다. '다정한 구원' 제목마저 딱 어울린다. 임경선 작가의 에세이는 이상하게 공감이 많이 간다. 그녀와 비슷한 점은 1도 없는데 말이다. 이 책은 그녀의 딸과 함께 포루투갈의 리스본에 다녀온 여행기(?)다. 엄밀히는 여행기는 아니고, 사실 본인이 어린 시절 1년 동안 있었던 곳의 아빠와 엄마의 흔적을 찾아 떠나는 추억 여행이기도 했다. 스페인은 가봤지만, 포루투갈은 이름만 듣..
들어가며 회사 독서모임의 올해 마지막 책~ 찰스디킨스 선집! 엄청 두꺼운 3권의 책이 묶여 있다. 선집에는 '두 도시 이야기' ,'올리버 트위스트', '픽웍 클럽 여행기' 이렇게 두꺼운 3권의 책이 함께 포함되어 있다. 찰스 디킨스에 대해서는 이름만 익히 들어왔는데, 알고 보니 스크루지로 알고 있는 그 이야기 '크리스마스 캐롤'의 저자였다. 영국의 빅토리아시대의 시대상을 대변하는 영국인이 사랑하는 작가라 한다. 그중에 가장 얇아 보이고 왠지 끌리는 장화 모양의 "올리버 트위스트"를 선택했다. 너무 두꺼운 책은 또 읽다가 포기하는 경향이 있는데, 나의 선택은 훌륭했다. (하단에 함께 보면 좋을 위키백과 참고) 독후감 책 제목 올리버 트위스트는 우리의 주인공 이름이다. 아빠도 모르고, 엄마가(어여쁜 청순하고..
들어가며 책장에 꽂힌 책중에 아직 읽지 못한 책~ 아내가 산 책이다. 소설을 요즘 꽤나 멀리한 내가 제목 때문에 집은 책이기도 하다. 그냥 두근 두근했던 적이 언제였나? 해서 ^^; 이게 이미 영화화가 됐던 소설이다. 주인공이(엄밀히 말하면 주인공의 부모들이지만) 무려 강동원과 송혜교다. 내가 주인공이었으면(내용은 너무 슬프지만) 행복했을 것 같다. 나는 반전이 싫다! 독후감 두근두근 내 인생 Author : 김애란 지음 Publisher : 창비 Format : 356 pages, Paperback ISBN : 9788936433871 제목이 알콩달콩하지만, 내용은 그렇게 알콩달콩하지 않다. 조금은 슬픈 이야기. 조로증에 걸린 17살 아름이(남자다)의 이야기 어리지만 어른이 되버린... 많이 아프면, ..
들어가며 프랑수아즈 사강의 소설책이다. 최근에 SBS에서 방영했던 가슴 먹먹하다던 그 드라마와 제목이 똑같(?)지만 전혀 내용이 다른 바로 그 책! 클래식 음악을 좋아한다면 들어봤을만 한 브람스라는 작곡가! 하지만 이 책 역시 브람스와 거의 관련이 없다. 대화 내용에 잠깐 언급될 정도라서, 소설의 배경이 되었던 시점에 브람스란 작곡가가 나름 인기가 있었던 시기였나보다. '사랑'이 어떤 건지? 여전히 궁금하다면! 이 책을 읽어 볼 만하다. 독후감 브람스를 좋아하세요... Author : 프랑수아즈 사강 Translator : 김남주 Publisher : 민음사 Format : 160 pages, Paperback ISBN : 9788937461798 제목과 작가의 이름에 끌린책이다. '브람스를 좋아하세요...
독후감 전형적인 자기 계발서이다. 심리학 박사가 말해주는 인간 심리적인 부분에서의 접근. 내가 좋아하는 회사 선배님이 선물해주신 책이다. 원래 자기 계발서를 안 좋아하는 스타일이지만, 나를 생각해주신 선배님의 마음을 선물로 생각하고 읽었다. 하버드대 교수이지만, 중국계라서 동양적 마인드가 기본적으로 깔려 있어서 이해하기가 쉽다. 나를 비롯해서 모든 사람들은 자신이 항상 완전하지 못하다고 생각하다. 사실이기도 하고, 그래서 왜 어떤 점이 모자란 지 생각도 하고(이런 생각을 하는 사람이 훌륭한 사람이지만) 그걸 어떻게 하면 고칠 수 있을까? 하는 고민도 하는 사람이라면 굳이 이 책을 안 읽어도 되지 않을까? 나 역시 이책을 읽으면서 나에게 부족한 부분을 많이 발견했다. 책에서 박사님이 제시해준 해법들을 복기..